
 AI资讯网小编
AI资讯网小编 
>模型架构全面进化
>▸ 参数规模覆盖0.5B到72B七级梯度("B"代表十亿参数),同时提供基础版与指令微调版
>▸ 采用18万亿tokens超大规模预训练("T"代表万亿量级)
>▸ 上下文窗口扩展至128K tokens,长文本生成能力突破8K tokens
>核心能力飞跃提升
>▸ 结构化数据处理专家:表格解析与JSON格式生成准确率提升40%
>▸ 多语言大师:支持中/英/法/西等29种语言的无缝切换
>▸ 角色扮演大师:系统提示适配性增强300%,打造更自然的对话体验
>技术突破三大维度
>1️⃣ 语义理解革命:通过多模态数据预训练,实现文本、图像、音频的联合表征
>2️⃣ 人机协作进化:工具调用响应速度提升60%,AI Agent交互更智能
>3️⃣ 行业适配升级:金融文本生成、代码解释等专业场景准确率达SOTA水平
论文:2025.01.03V2_Qwen2.5 Technical Report
论文地址:https://arxiv.org/pdf/2412.15115
代码:https://github.com/QwenLM/Qwen2.5
01
—
背景和贡献
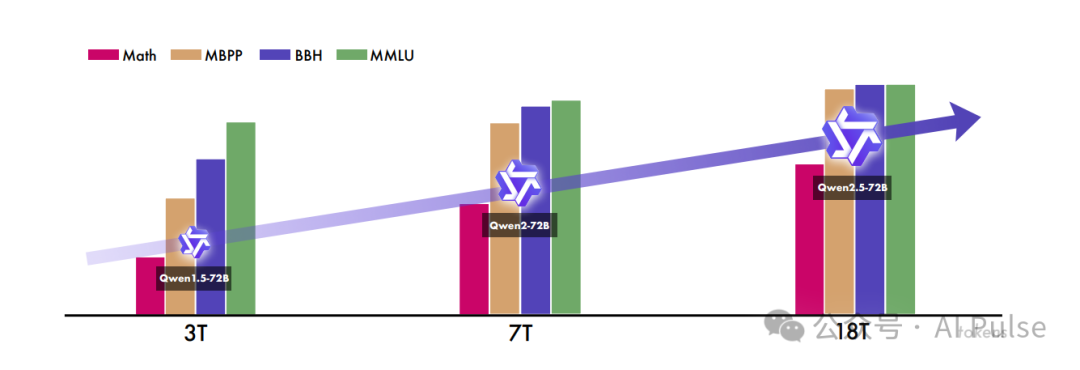
>随着AGI(人工通用智能)的快速发展,大型语言模型(LLM)在语言理解、生成和推理方面展现出“涌现能力”。模型规模扩大、数据质量提升及训练方法优化(如预训练+微调+RLHF)是主要驱动力。
>开放权重模型的崛起:Llama、Mistral等开源模型降低了LLM的使用门槛,促进了社区协作与创新。Qwen系列作为中文社区的代表模型,持续迭代以满足多样化需求。>贡献:- >模型规模扩展:Qwen2.5覆盖0.5B到72B参数,并引入MoE(混合专家)变体(Turbo和Plus),在资源受限场景下提供高性价比选择。
- >数据质量提升:预训练数据从7万亿token增至18万亿,重点优化数学、代码和知识领域的数据混合与过滤。后训练阶段引入百万级有监督微调(SFT)样本,结合离线RL(DPO)和在线RL(GRPO)增强人类偏好对齐能力。
- >功能改进:支持更长文本生成(8K→1M token)、结构化数据解析(JSON/表格)、工具调用等,提升实际应用能力。
02
—
主要方法
-
>基础架构>:基于Transformer解码器,采用GQA(分组查询注意力)、SwiGLU激活函数、RoPE(旋转位置编码)等技术优化计算效率与长上下文处理。
-
>MoE架构>:将标准FFN层替换为多专家层,结合细粒度专家分割和共享路由机制,提升模型性能。
-
>分词器>:基于BBPE(字节级BPE),词汇量151,643,新增工具调用专用控制token,统一各模型分词策略。
>数据优化>:
-
>高质量数据过滤与多维度评分。
-
>引入数学(Qwen2.5-Math)和代码(Qwen2.5-Coder)领域专用数据。
-
>合成数据生成与严格过滤。
>长上下文训练>:
-
>分阶段扩展上下文长度(4K→128K token),采用YARN和DCA(双块注意力)技术提升长序列建模能力。
-
>Qwen2.5-Turbo支持百万token上下文,通过渐进式训练策略平衡效率与性能。
-
>有监督微调(SFT)>:针对长文本生成、数学推理、代码生成等任务构建专用数据集,结合反向翻译、代码验证、多语言对齐等技术提升模型能力。
-
>两阶段强化学习>:离线RL(DPO)>:基于执行反馈和答案匹配优化数学、代码等确定性任务。在线RL(GRPO)>:利用奖励模型(RM)优化生成结果的真理性、无害性、简洁性等人类偏好指标。
03
—
实验与结果
>3.1.基准测试表现
- >通用任务:Qwen2.5-72B-Instruct在MMLU、BBH等基准上超越Llama-3-405B,部分任务领先(如MMLU-Pro)。
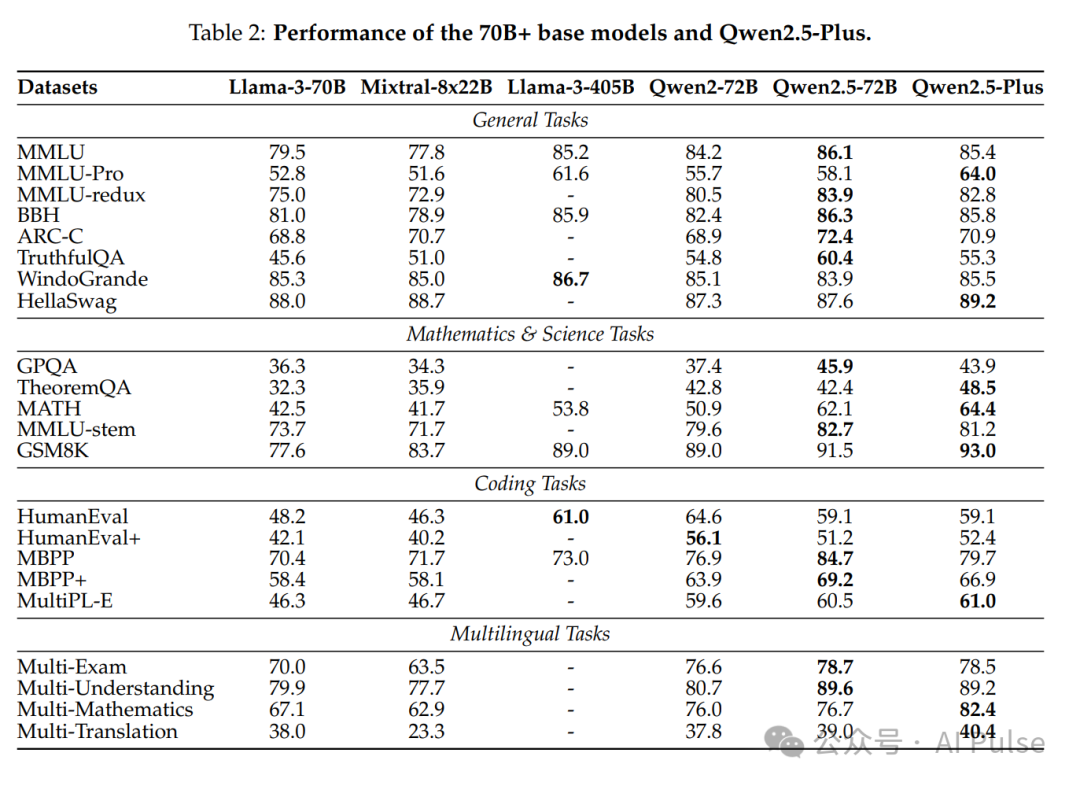
- >数学与代码:MATH数据集上,Qwen2.5-72B得分62.1(对比Llama-3-405B的53.8)。HumanEval代码生成任务中,Qwen2.5-72B达到86.6分,接近GPT-4o-mini(88.4)。
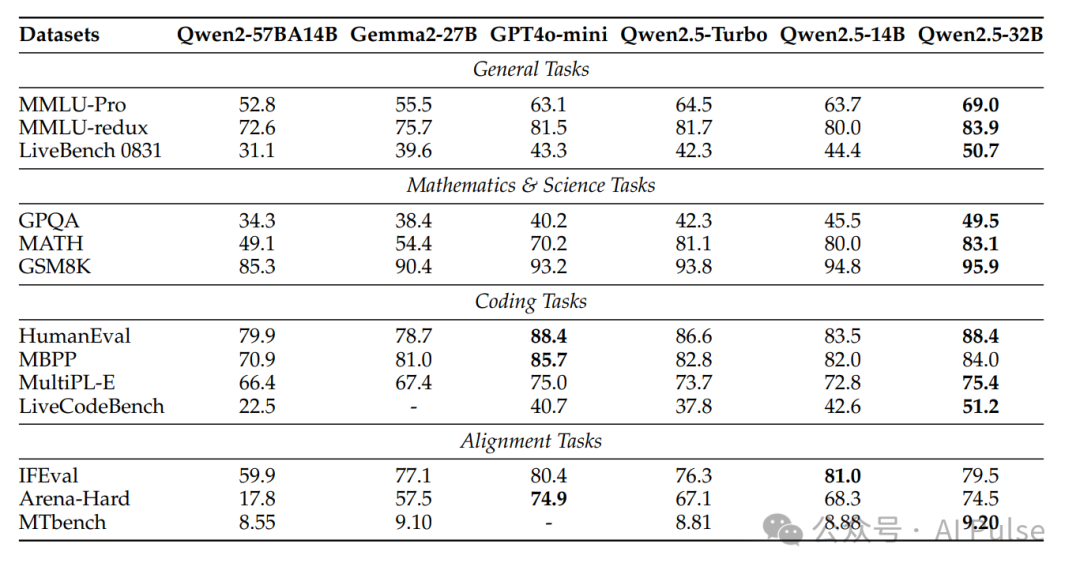
- >多语言能力:在阿拉伯语、日语等多语言MMLU变体上表现优异,跨语言迁移能力显著。
- >RULER基准:Qwen2.5-72B-Instruct在128K token长度下准确率达88.4%,优于GPT-4(81.2%)。
- >Passkey检索:Qwen2.5-Turbo在1M token长度下实现100%准确率,推理速度提升3.2-4.3倍。
转载请注明出处: CHATWEB
本文的链接地址: https://www.chatweb.com.cn/post-132.html
-

推荐:一个先进的AI视频生成器!搞事情?
2025/04/06
-
GPT-4o杀疯了:现在修图靠‘说’就行!连我妈都做出了电商广告图
2025/03/30
-
DeepSeek新功能:批量生成视频,100个分镜视频只需几分钟!
2025/03/30
-
30家值得关注的AI公司精选了国内最值得关注的30家AI公司
2025/04/19
-
清华学霸团队出品的Kimi,好用到爆!
6天前
-
Kimi的社区产品刚刚曝光,和OpenAI的是一件事吗?
6天前
-
Prompt Optimizer:AI提示词优化工具
6天前
-
DeepSeek使用指南:从入门到精通
6天前
-
Google Gemini推出了Gems,可创建个人专属AI代理
5天前
-
北京大学DeepSeek与AIGC应用手册(全)
6天前










 EMLOG
EMLOG
暂无评论