
 AI资讯网小编
AI资讯网小编
近年来,AI 技术飞速发展,很多朋友都投身于 AI 模型的训练。然而,相较于模型的获取,高质量的数据往往更加难以收集。一方面,互联网每天都在源源不断地产生新数据,另一方面,各大网站普遍设有反爬机制,阻止自动化程序抓取信息。在这种情况下,动态代理服务成为破解难题的关键工具。通过动态代理,我们的爬虫程序可以模拟不同的用户身份,在访问网站时伪装 IP 地址,从而有效降低被封禁的风险。
作为行业的先行者,亮数据是最早开展代理 IP 服务的企业之一,经过多年积累,已构建起庞大且稳定的代理 IP 资源。借助其代理服务,我们可以显著提高爬虫程序的访问成功率,从而更高效地获取数据,助力 AI 模型的训练。
维基百科是 AI 领域的重要数据来源,广泛用于训练 RoBERTa、XLNet 和 LLaMA 等大模型。本次,我们将以采集维基百科数据为例,分别面向零经验的初学者和熟练开发者介绍如何结合爬虫技术与动态代理,高效获取训练数据。
新手之选:网页抓取API如果你是第一次接触爬虫技术,可能会感到有些无从下手,不知道该从哪里开始。别担心,其实并没有那么复杂!你可以尝试使用 亮数据的网页抓取API (https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_man202503&promo=APIS25),它已经为100多个网站量身打造了不同的爬虫方案,覆盖了各种应用场景。而且,你无需编写复杂的代码,只需通过可视化界面进行简单配置,就能轻松获取所需的数据。
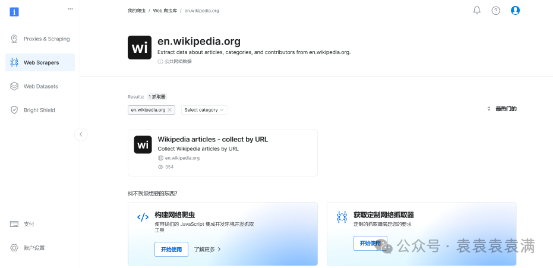
登录以后进入控制台,点击网页抓取API,选择进入到Web爬虫库。Web爬虫库中有各种网站的丰富爬虫应用可以直接使用。

在其中定位到Wikipedia网站,可以看到有一项抓取Wikipedia文章的应用,这就是我们的目标了。
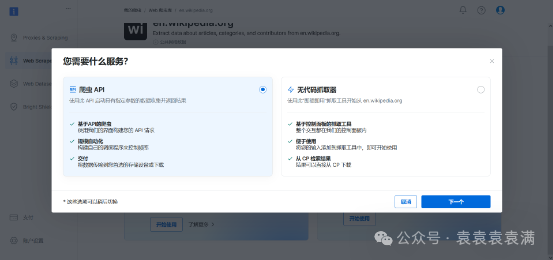
点击以后选择爬虫API,它相比无代码抓取器有更多的定制空间。
在爬虫的设置界面中,进入API请求构建器,在这里配置一下令牌,还可以在网址的部分配置采集的页面。
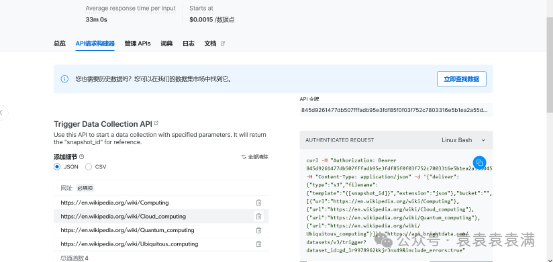
而在词典中可以管理要采集的字段,如果没有你需要的字段,也可以提交工单等待工作人员优化。
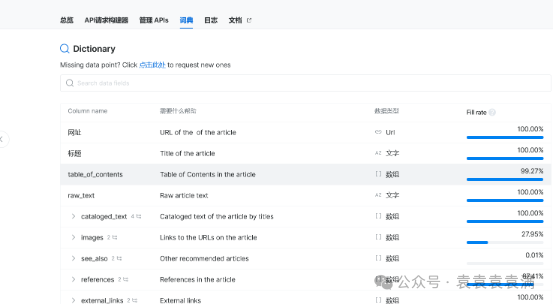
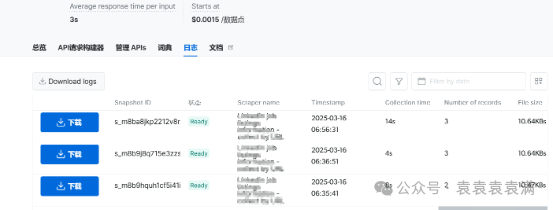
配置完成后点击右上角开始运行。稍等片刻,就可以在日志中下载结果。是不是很简单呢?
 可靠之选:动态住宅代理
可靠之选:动态住宅代理
如果你已经对爬虫技术比较熟悉,并且有定制化采集需求,或者想要将数据抓取功能集成到自己的应用中,那么网页抓取 API 可能会有些局限。这时候,不妨试试 动态住宅代理(https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_man202503&promo=RESIYERA50),搭配自己编写的爬虫程序,自由度更高,也更灵活。亮数据的动态住宅代理服务拥有超过 7200 万个住宅 IP,覆盖全球多个国家和地区,IP 质量稳定,成功率高,而且价格公道,性价比极佳。对于需要长期、大规模数据采集的开发者来说,这是一个非常可靠的选择。
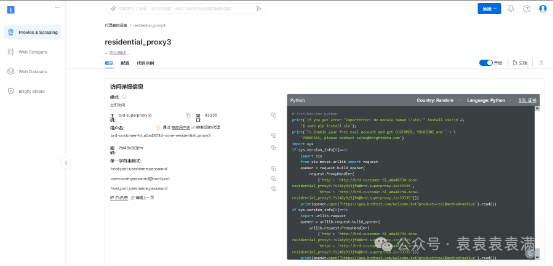
登录之后,在控制面板的代理&抓取基础设施中选择动态住宅IP。
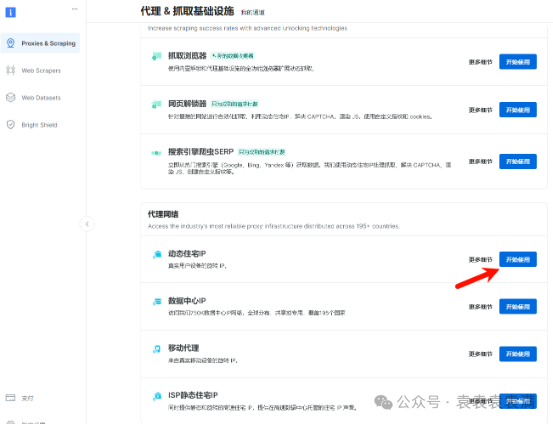
之后在代理设置界面填写名称,选择要选购IP的地点,之后就可以开始使用。

确认之后就可以看到代理服务的主机名、用户名和密码。将它们复制下来,之后会用到。同时将本地IP添加到白名单中。
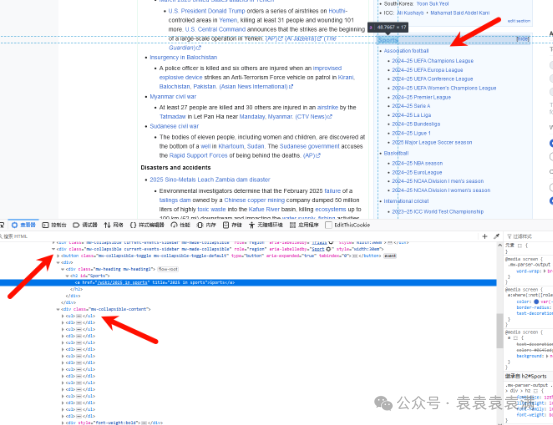
之后我们开始编写爬虫。我们这次爬取Wikipedia的最近体育新闻板块,这个功能在网页抓取API中没有提供,所以需要我们自行开发。注意到这一个板块可以使用title="2025 in sports"定位标题,然后向上选取四层定位到整个栏目。然后向下选取到第二个div中的ul和dl即为所需。
首先,我们将代理服务器、请求头和url定义为一些常量便于管理。接下来,我们创建一个带有代理的opener对象,和一个包含目标URL和请求头的请求对象。随后,发送HTTP请求,获取页面的HTML内容,并使用lxml库将HTML解析为可操作的XML树结构。
proxy = {'http': 'http://brd-customer-hl_a0a48734-zone-residential_proxy3:7sl48y9j3jfm@brd.superproxy.io:33335'}proxy.io:33335',
'https': 'http://brd-customer-hl_a0a48734-zone-residential_proxy3:7sl48y9j3jfm@brd.superproxy.io:33335'}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0"}
url = "https://en.wikipedia.org/wiki/Portal:Current_events"
opener = request.build_opener(request.ProxyHandler(proxy))
req = request.Request(url=url, headers=headers)
html = opener.open(req).read()
接下来,首先定位到页面中 “2025 in sports” 这个链接所在的 HTML 节点,并向上回溯以找到包含完整新闻内容的 div 元素。随后,进一步解析该 div,提取其中的新闻标题和超链接,将其整理成一个字典格式的数据结构。其中,result字典用于存储爬取到的新闻内容,年份被固定设置为 2025,而新闻条目被存入 content 字段。
root = etree.HTML(html)
div = root.xpath('.//a[@title="2025 in sports"]/../../../..')
ilist = div.xpath('./div[1]')
result = {"time": 2025, "content": []}
for item in ilist.xpath('./ul'):
temp = []
for lis in ilist.xpath('./dl/dd/ul/li'):
for li in lis:
link = li.xpath('./a/@href')
name = li.xpath('./a/@title')
temp.append({"name": name, "link": link})
result["content"].append({i7sl48y9j3jfm@brd.superproxy.io:33335'}proxy.io:33335',
最后,将获取到的新闻信息转换为字符串,并将其写入到本地文件中,以便后续处理或分析。
with open('wiki_sport.txt', 'w') as f:
f.write(str(result))
完整代码如下:
from urllib import request
from lxml import etree
proxy = {'http': 'http://brd-customer-hl_a0a48734-zone-residential_proxy3:7sl48y9j3jfm@brd.superproxy.io:33335',
'https': 'http://brd-customer-hl_a0a48734-zone-residential_proxy3:7sl48y9j3jfm@brd.superproxy.io:33335'}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0"}
url = "https://en.wikipedia.org/wiki/Portal:Current_events"
opener = request.build_opener(request.ProxyHandler(proxy))
req = request.Request(url=url, headers=headers)
html = opener.open(req).read()
root = etree.HTML(html)
div = root.xpath('.//a[@title="2025 in sports"]/../../../..')
ilist = div.xpath('./div[1]')
result = {"time": 2025, "content": []}
for item in ilist.xpath('./ul'):
temp = []
for lis in ilist.xpath('./dl/dd/ul/li'):
for li in lis:
link = li.xpath('./a/@href')
name = li.xpath('./a/@title')
temp.append({"name": name, "link": link})
result["content"].append({item.xpath('./li/a/text()'): temp})
with open('wiki_sport.txt', 'w') as f:
f.write(str(result))
在 AI 训练的道路上,高质量的数据是不可或缺的,但获取这些数据往往面临诸多挑战。网站的反爬机制让直接抓取变得困难,而手动收集数据又过于低效。在这样的背景下,动态代理服务成为了一种高效、可靠的解决方案。
亮数据作为行业的佼佼者,提供了强大的代理 IP 资源,无论是刚入门的数据采集爱好者,还是经验丰富的开发者,合理利用爬虫技术与代理服务,都能帮助我们在 AI 领域迈出更坚实的一步。希望本次的分享能为你的数据获取任务提供实用的思路和工具,让 AI 训练更加顺畅。
最近亮数据也开启了一系列活动,感兴趣的朋友不妨了解一下:
- 亮数据住宅代理全部套餐5折!错过等一年!所有新老客户均可使用,即可直接享受折扣:https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_man202503&promo=RESIYERA50
- 亮数据网页抓取API,全线75折!有效期6个月!所有新老客户均可使用,即可直接享受折扣:https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_man202503&promo=APIS25
我想设计一节利用曼陀罗绘画疗愈的心理健康课,其中绕不开的知识点就是荣格利用曼陀罗绘画自我疗愈的内容。我把这些内容整合到了一个小视频里。
我完成的视频是这样的:
以下详细介绍这个小视频的制作过程。
一、利用DeepSeek生成文案
如果直接让DeepSeek生成文案,可能不那么容易符合自己的预期,其实我在网络上已经找到一篇短文,但是如果直接复制别人的短文,会涉嫌侵权。所以我对DeepSeek说:“以下文章帮我稍微改写一下能让初中生理解:……”DeepSeek很快就帮我把内容改好了,这样就不会涉及到侵权了,呵呵。
以下是DeepSeek帮我改好的内容:
荣格是心理学大师。他原本跟随弗洛伊德学习,但因为对人性理解不同而分道扬镳。分手后,荣格经历了很长一段迷茫时期。在这段艰难时光里,他无意中发现画曼陀罗(一种圆形图案)能帮助自己走出心理困境。
荣格在自传中说:"当我开始画曼陀罗时,发现自己走过的所有路、经历的所有事,最终都指向一个中心点。我渐渐明白,曼陀罗就是这个中心,是我们人生的指南针。"
他认为曼陀罗能帮助人们整合内心世界,保持心理健康。通过画曼陀罗,人们可以发现自己的潜能和特点。后来,这发展成了一种艺术治疗方法。
画曼陀罗有四大好处:
1. 保护作用:情绪激动时画曼陀罗,能让人平静下来
2. 稳定心神:思绪混乱时,能帮助我们重新找到方向
3. 集中注意力:能让我们的注意力更集中
4. 整理内心:长期坚持画,能帮助我们梳理内心世界
有了文本,我们就可以让豆包帮我们生成相应的图片。
二、利用豆包生成图片
首先进入豆包,点击左下角的“对话”,点击“AI图片生成”,
我把文案的第一句话复制给豆包

然后点击右侧蓝色向上的箭头,豆包会自动画出与之相匹配的图画,如果你对这些画还不满意,可以点击“再次生成”

我们继续把文案分成一段一段的,分别复制给豆包,豆包会相应的生成与之相匹配的图画。

当然,我们如果想要对图片进行调整,可以点击“AI编辑”进入编辑页面

点击“消除”,在有字的地方进行涂抹,可以消除字迹


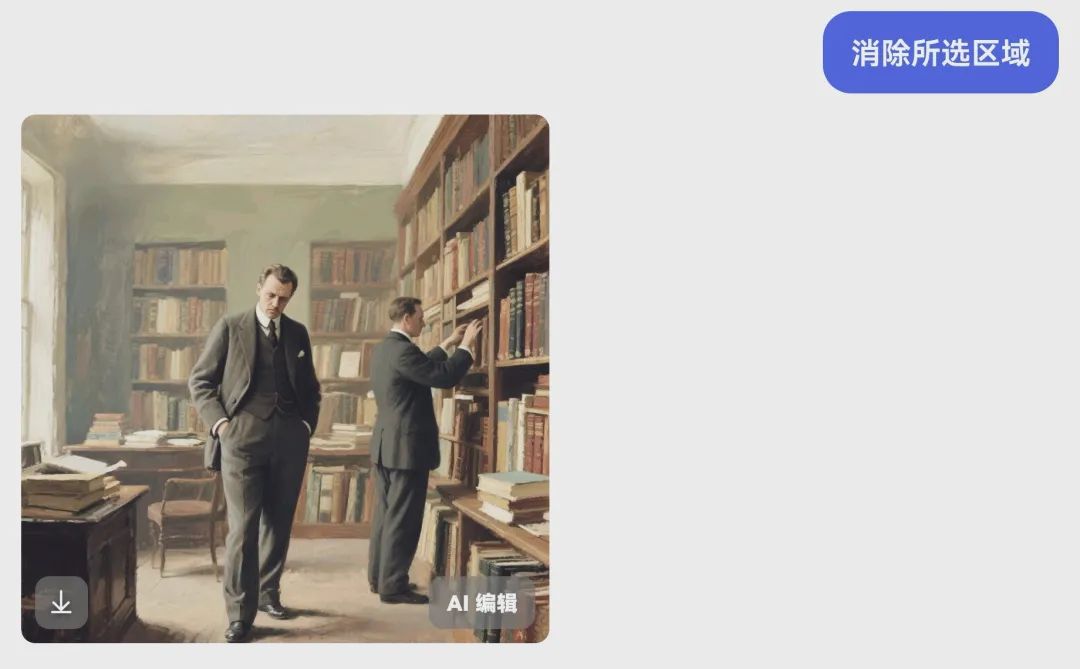
再次点击“AI编辑”,点击“原比例”改为我们需要的比例,我选择16:9,点击“扩图”,可以生成理想尺寸的图片

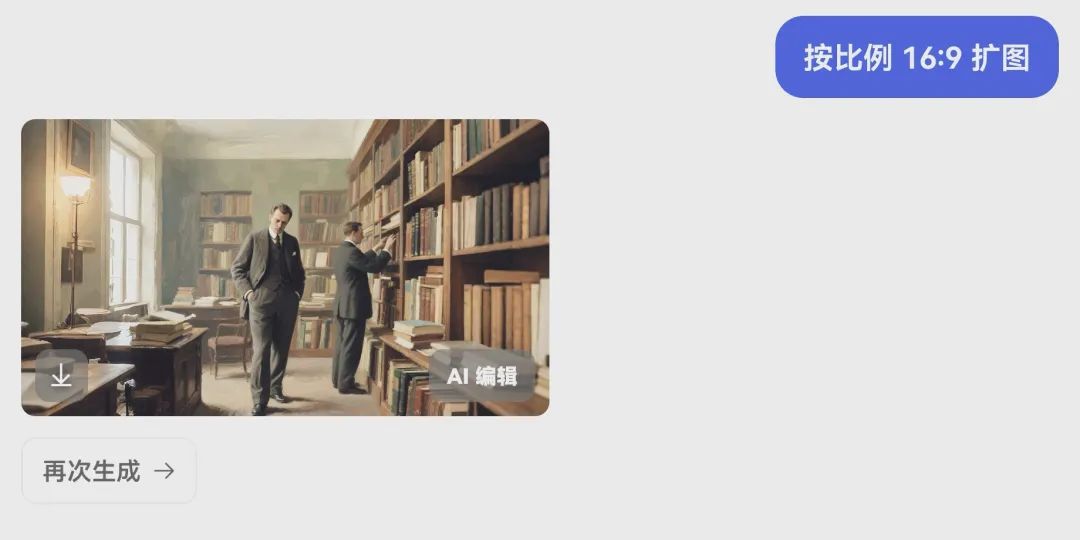
按照此法,我总共做了14张比例是16:9的图片。图片的制作就完成了。
三、利用剪映整合出视频
打开剪映,点击“图文成片”
在打开的页面中点击“自由编辑文案”
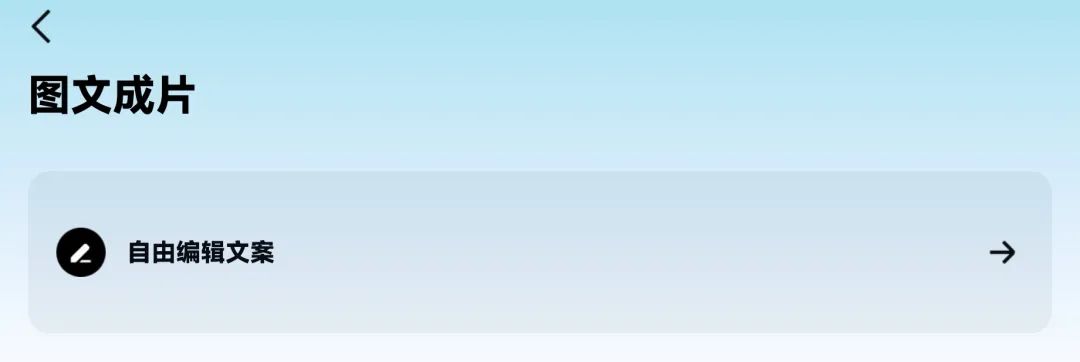
进入后把准备的文案复制粘贴进去,点击“应用”

在弹出的对话框中选择“使用本地素材”

稍微等待……

在随后进入的页面中,点击“音色”和“背景音乐”,可以对二者进行更换调整。随后再点击“添加素材”
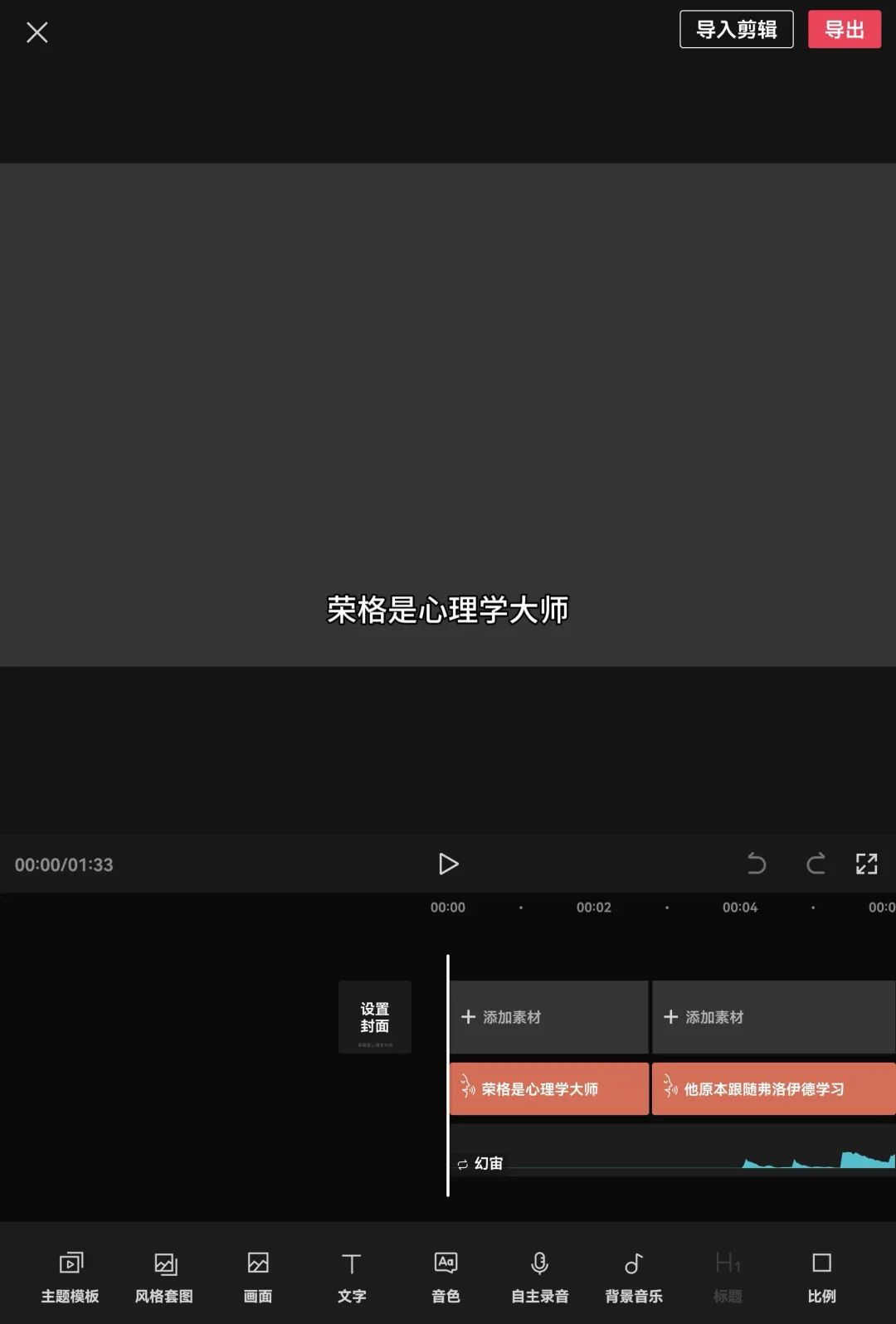
从跳出的页面上点击时间轴下面的第一个长方形,再点击“照片”,从弹出的照片缩略图里找到并点击和文案第一句话相匹配的图片,图片就会被匹配到相应的位置
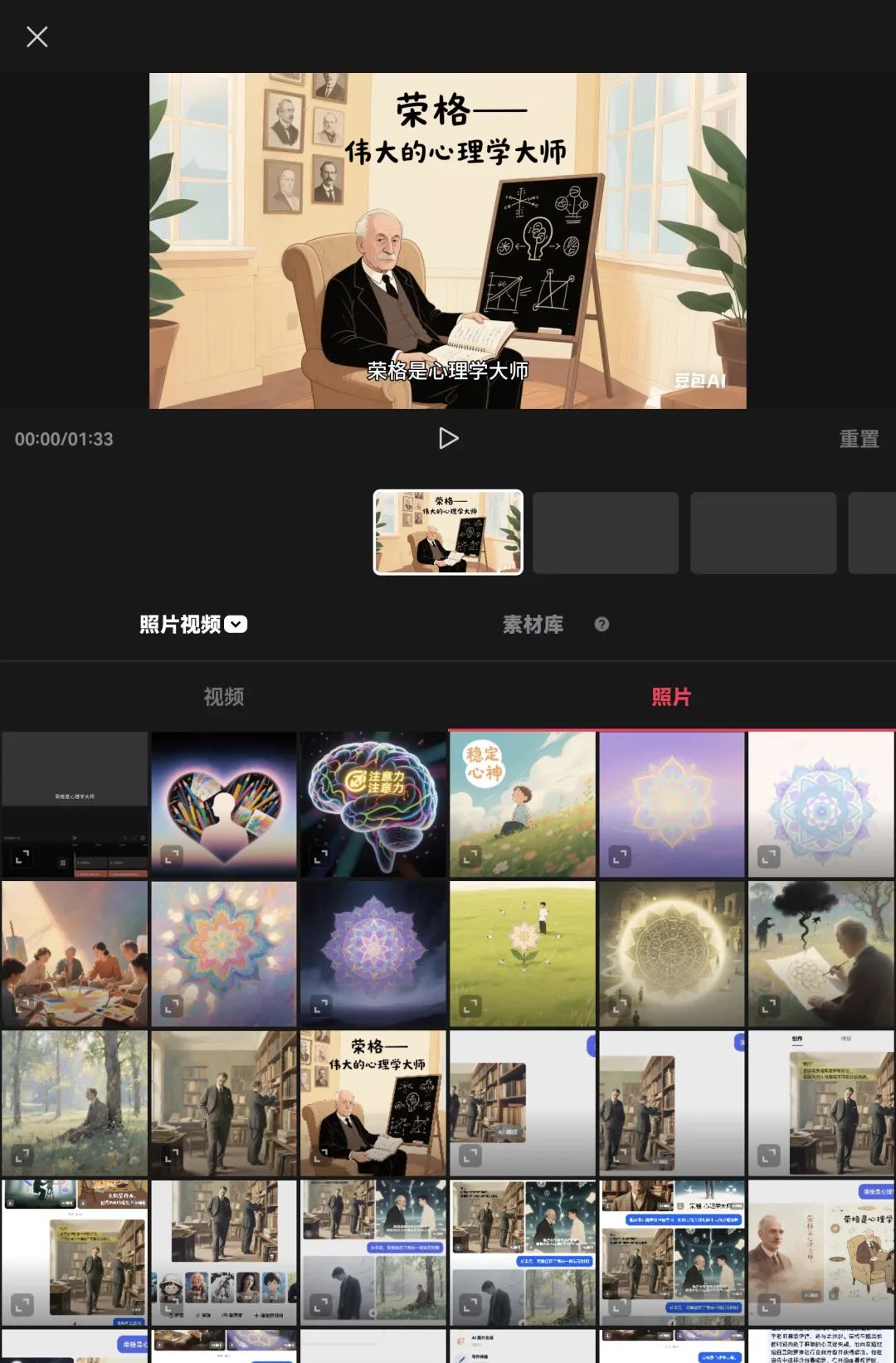
再点击时间轴下面的第2个长方形,继续点击与文案中第2句话相匹配的图片,这样第2个图片就被匹配到相应的位置。以此类推,为每一段话都匹配上相应的图片。
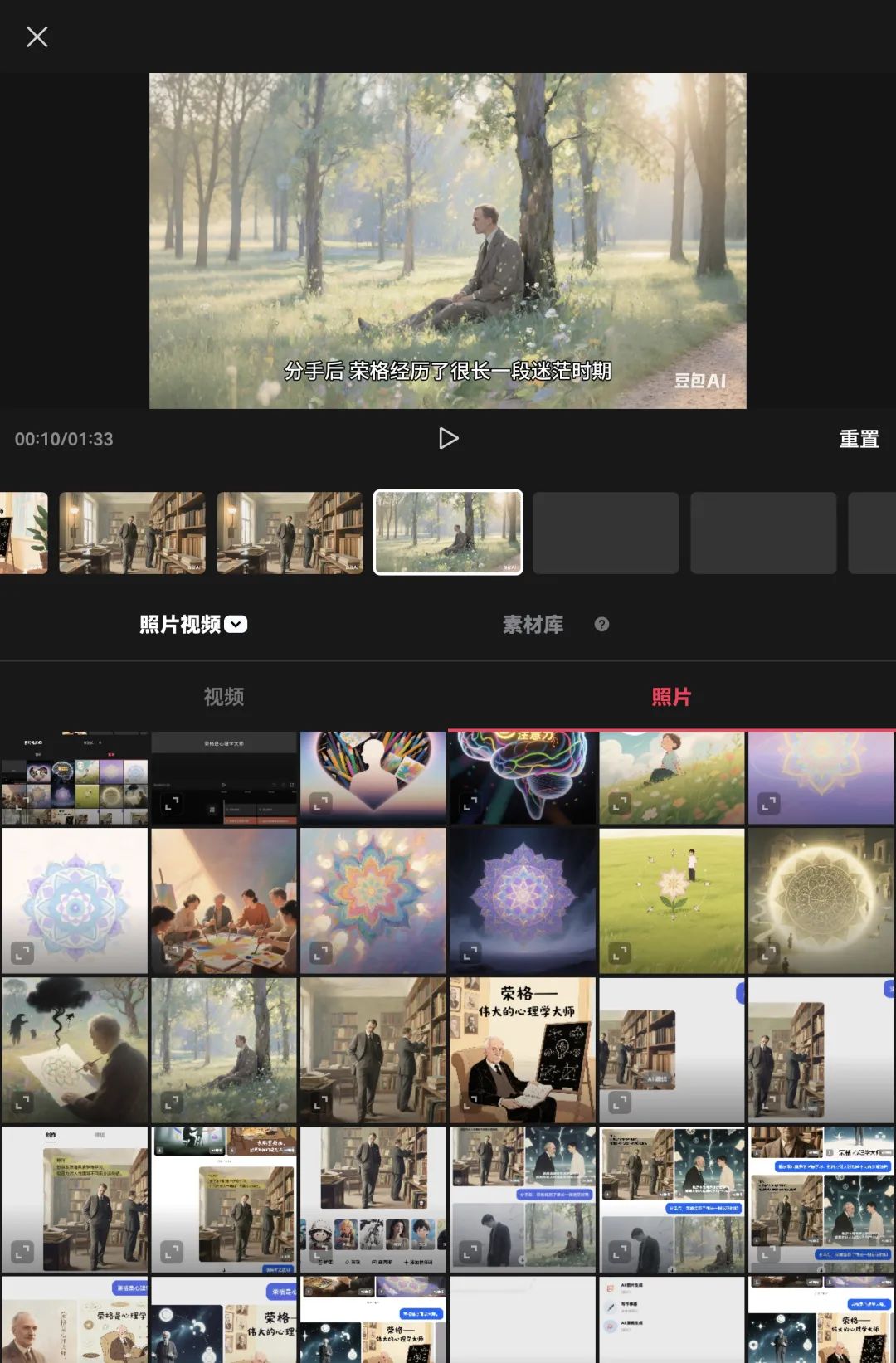
直到添加完最后一张图片。点击小三角可以预览视频。
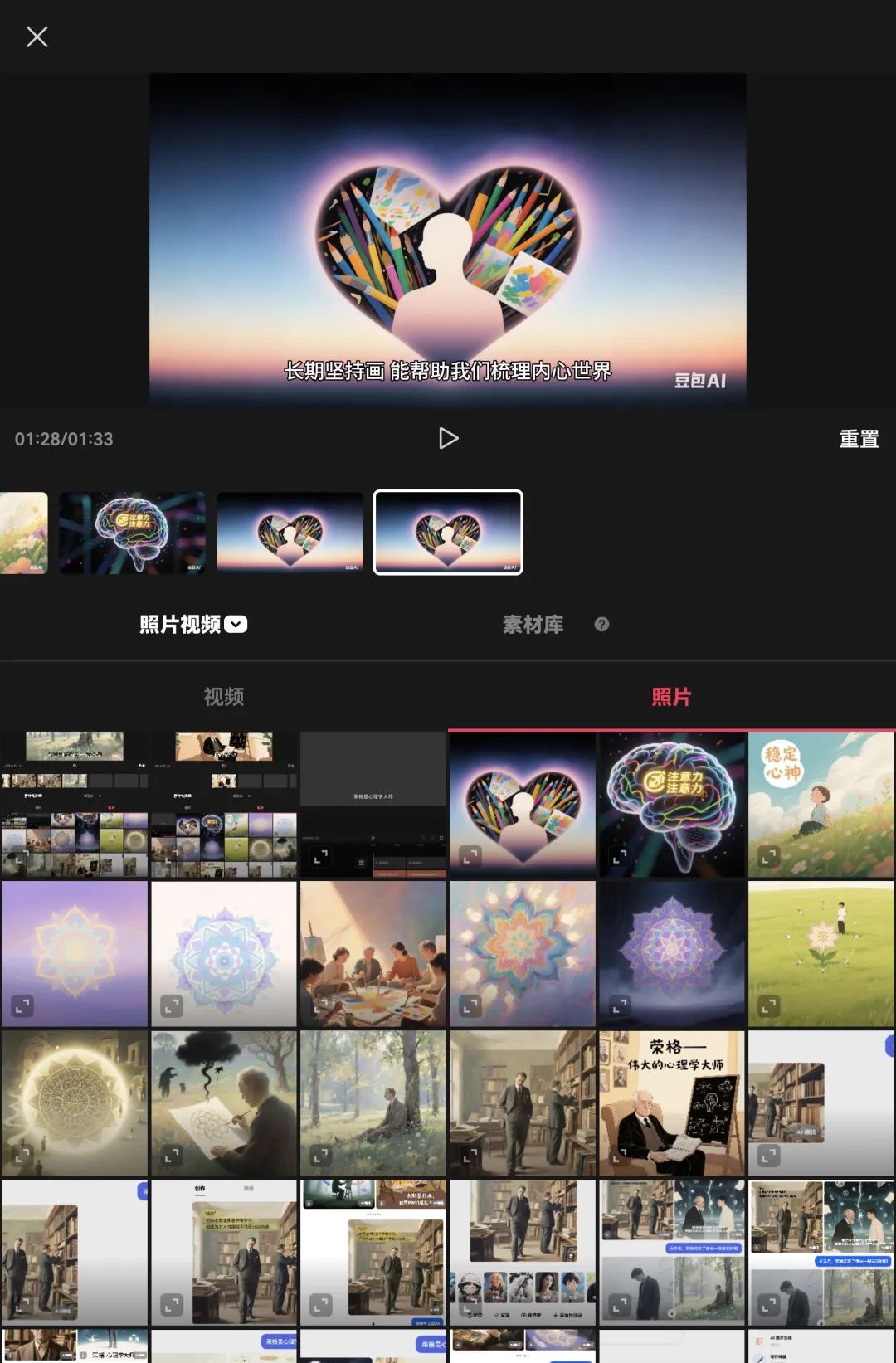
点击左上角的叉号,退出这个添加照片的编辑界面,进入到以下界面。点击小三角符号,可以观看视频,点击“导出”就可以保存视频啦!
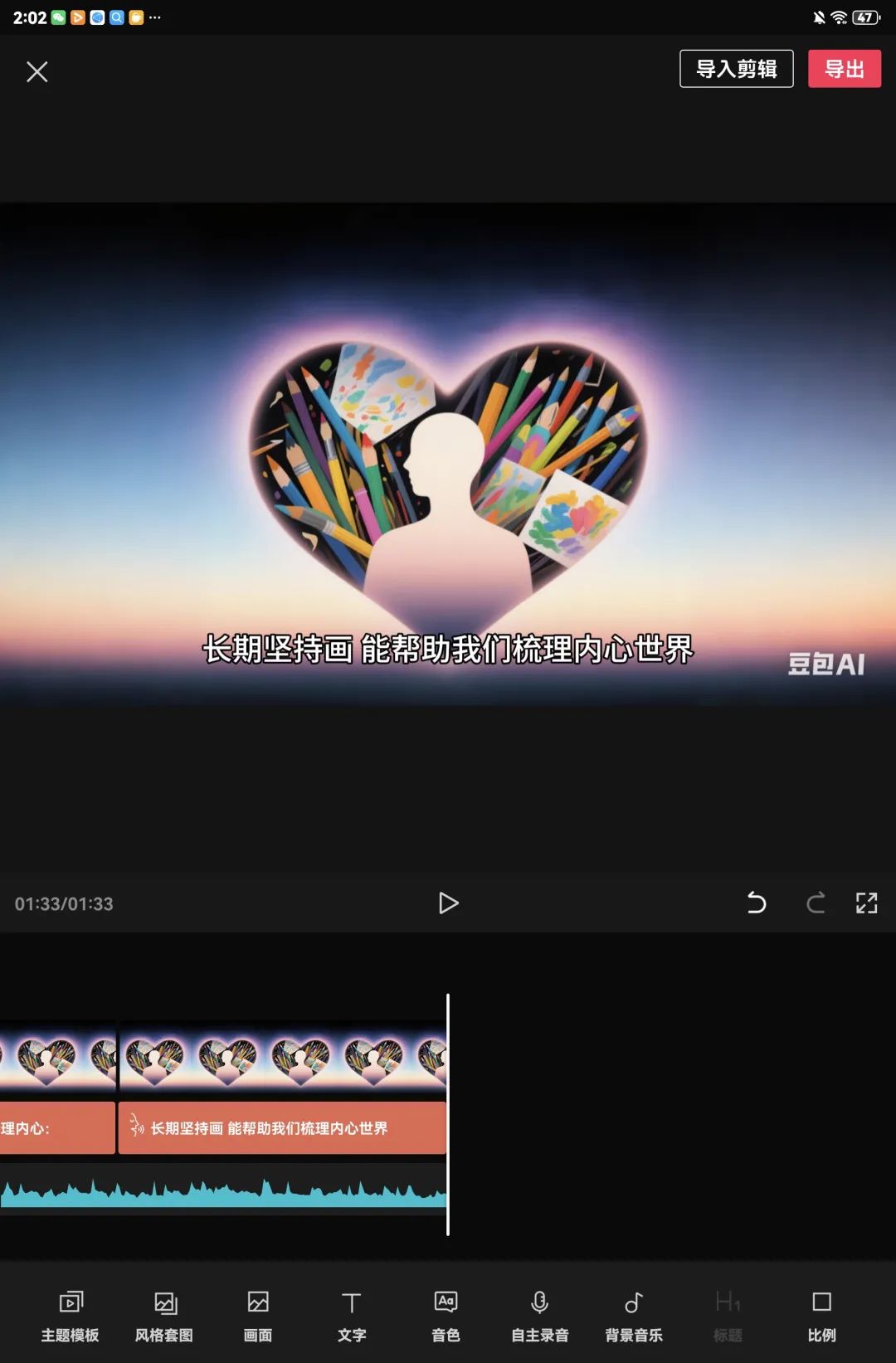
刷到我文章的小伙伴们,快去试试吧~
转载请注明出处: CHATWEB
本文的链接地址: https://www.chatweb.com.cn/post-146.html
-

5 分钟教你用 DeepSeek + 讯飞星火实现 AI 数字人实时对话,老师必看!
2025/03/30
-
腾讯 ima 最强,没想到被这款AI工具彻底打脸!
2025/03/30
-
424万家!中国AI公司爆发式增长,水分也不少...
2025/04/19
-
用 AI 制作万物花开视频,绝了,和抄作业一样简单!
2025/03/30
-
近期又一热词:“元宝”是什么?
2025/04/19
-
全网最全 Kimi 应用指南,高手必备!(建议收藏)
6天前
-
豆包 AI 测评:你的智能聊天小助手!
2025/04/19
-
AI提示词设计:一篇文章带你从入门到精通,轻松掌握高效提示词技巧!
2025/04/19
-
高校教师的智能助手,全网最全Kimi使用指南
6天前
-
腾讯良心出品,普通人也能快速AI生成自己的3D模型
6天前











 EMLOG
EMLOG
暂无评论