
 AI资讯网小编
AI资讯网小编
【图2】Framework示意图。大语言模型(LLM)预训练、LLM监督微调(SFT)、嵌入弱监督训练以及嵌入监督训练
Conan-embedding-v2训练过程分为四个阶段,每个阶段在数据格式和损失函数上均有所不同。在大语言模型(LLM)训练阶段(第1和第2阶段),我们加入了嵌入数据,以更好地使LLM与嵌入任务对齐。在弱监督训练阶段,我们使用与LLM监督微调(SFT)相同的配对数据,并应用软掩码来弥合LLM与嵌入模型之间的差距。在监督训练阶段,受益于LLM训练,我们引入了跨语言检索数据集和动态硬负例挖掘方法,以提高数据的多样性和价值
LLM训练
我们设计了Conan-1.4B,包含8层Attention Layers,Hidden Size为3584,最长上下文32k。它的参数量是1.4B,能够在较少的参数下提供更大的Embedding维度。
我们从基础的字母、符号上,在约40万条多语言语料上训练了Conan的BBPE分词器,目标词表大小15万,完成了词表训练。我们在中英语料上评估了自训练Tokenizer的编码效率。和QWen的Tokenizer相比。Conan的分词器表现良好。
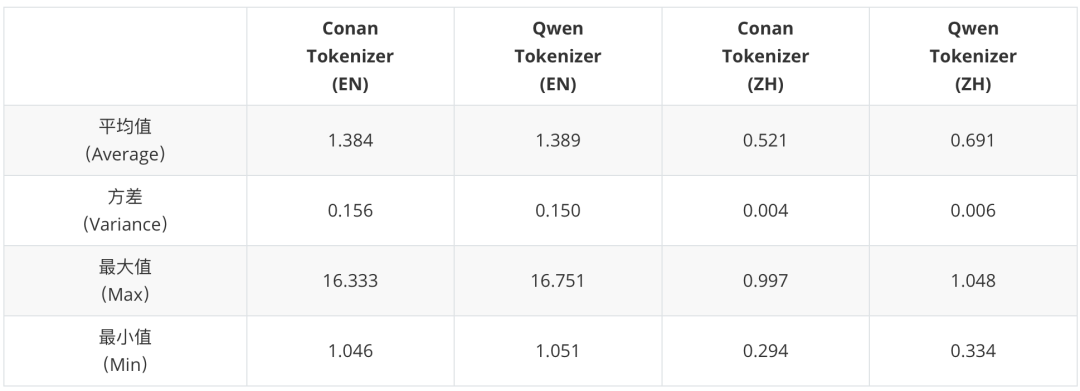 【表1】Conan分词器编码效率对比
【表1】Conan分词器编码效率对比
如图2所示,我们首先在约3T Tokens的通用数据上对模型进行了预训练,重点增加了针对性的适合做Pair的数据。我们采用了Internlm2中描述的标准数据过滤方法进行过滤。
随后,我们收集了约6亿条监督微调(SFT)数据,这些数据以配对数据(Query - Positive Sample)的形式组织,格式为指令、输入和输出。
Embedding训练弱监督训练
在嵌入训练中,我们首先实施了弱监督训练,以使模型初步学习嵌入的表示。 在此阶段,我们使用与LLM监督微调相同的数据,但采用不同的数据格式和损失函数。 具体来说,我们将指令和输入作为查询,输出作为正例段落。
为了确保更高的数据质量,我们使用gte-Qwen2-7B-instruct模型进行评分,并丢弃得分低于0.4的数据。
为了高效且有效地利用配对数据,我们在训练中采用了InfoNCE损失函数,并结合In-Batch Negative采样,其公式如下:
其中,表示正例样本的查询,表示正例样本的段落,表示批次中其他样本的段落,这些样本被视为负例。
监督训练
在弱监督训练之后,我们针对不同的下游任务进行任务特定的微调。 如图2所示,我们将任务分为四类:检索、跨语言检索、分类和语义文本相似度(STS)。前三类任务包括一个查询、一个正例文本和一些负例文本,使用经典的InfoNCE损失函数。STS任务涉及区分两个文本之间的相似度,其经典损失函数为交叉熵损失。我们采用CoSENT损失来优化STS任务,其公式如下:
其中,,是和之间的真实相似度,表示和之间的余弦相似度,是尺度温度参数。
主要策略SoftMask
在LLM的训练阶段,使用因果掩码(causal mask)来确保当前token无法访问后续token,这适用于token级别的语言建模。然而,嵌入训练需要对句子进行整体理解,使用双向掩码(bidirectional mask)进行向量级别的建模。这两种掩码之间存在几个关键差距。
首先,由于因果掩码的上三角部分全为零,在前向传播过程中该区域的注意力权重未被使用。 当直接切换到双向掩码时,这些权重需要经过学习过程才能生效。 其次,因果掩码是满秩的,具有更强的表达能力,而双向掩码的秩始终为1。 如果在弱监督微调阶段直接从因果掩码切换到双向掩码,训练可能会由于低秩而快速收敛,但容易陷入局部最优,使得进一步优化变得困难。
如图2所示,为了解决这些差距,我们引入了一种新颖的软掩码机制。首先,为了解决注意力权重的问题,我们在软掩码中引入了一个项,其中是我们的调度函数,使掩码从0逐渐过渡到1,从而使模型能够逐步更新这些参数。被设置为总步数以进行归一化。 定义如下:
其次,由于弱监督训练需要学习更丰富的特征表示,我们提出了一种动态降秩方法。我们使用表示掩码矩阵。 我们采用了一种简单的方法,将的前列值设置为1,从而使其秩为。 通过将其与我们的权重调整方法结合,靠近开头的值会更快地过渡到1。软掩码的公式如下:
i<j表示我们正在修改上三角部分的值。是训练序列长度。我们确保最大值为1,且靠前的列更快达到1。 这不仅使秩逐渐降低,还符合从前到后阅读的趋势,其中权重逐渐减小。
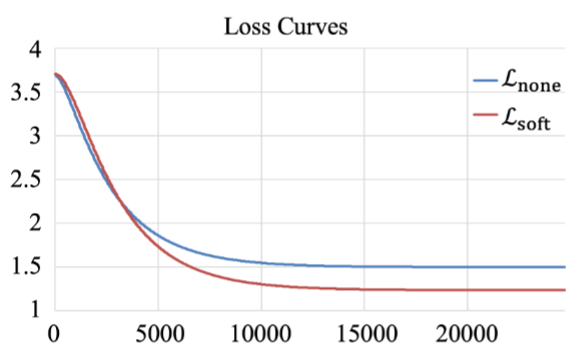
【图3】使用软掩码机制前后的损失曲线对比
如图3所示,我们绘制了使用和不使用软掩码机制的损失曲线。结果表明,初始阶段,使用软掩码的损失下降速度比不使用软掩码的损失更慢。然而,使用软掩码的最终损失更低。 这表明软掩码方法使模型在训练早期能够学习到更全面的特征表示。
随着训练的进行,秩被降低以保留最重要的特征,这种降秩过程作为一种正则化手段,有助于防止过拟合。
Cross-lingual Retrieval Dataset
为了开发一个多语言LLM,我们的目标是让Conan-embedding-v2能够学习不同语言的表示。 以往的研究主要集中在直接使用多语言语料库进行微调,或者使用平行语料库(其中文本是翻译的),但往往忽略了语言之间的内在联系。 为了解决这个问题,我们提出了一个跨语言检索数据集(CLR),通过跨语言搜索整合不同语言的表示,从而缩小它们之间的表示差距。
我们从现有的检索数据集开始,并将其扩展以支持跨语言检索。为了减少工作量,我们仅使用Qwen2.5-7B翻译数据集的查询部分。例如,我们将MSMARCO(一个英语检索任务)子集中的查询翻译为中文,以实现中文到英文的检索。同样,我们将这种方法应用于其他任务,将查询翻译为支持26种语言之间的跨语言检索,最终生成了大约1000万对数据。

【图4】在跨语言检索数据集训练前后的嵌入分布对比
为了更直观地展示嵌入的分布,我们对嵌入分布进行了对比分析。 我们使用了Multilingual Amazon Reviews Corpus,该语料库未包含在我们的跨语言检索数据集中。该语料库包括英语、日语、德语、法语、中文和西班牙语的评论。对于每种语言,我们从测试集中抽取了1000个句子。如图4所示,vanilla方法表示我们的模型未包含CLR数据集。六种不同语言的嵌入明显聚类,每种语言在分布空间中占据独立的区域。相比之下,我们的模型Conan-embedding-v2成功地将所有语言的嵌入整合到一个统一的分布中,展示了其在创建更一致的多语言表示方面的有效性。
动态难负例挖掘
该策略的详细介绍请参考我们Conan-V1的技术报告Conan-Embedding-V1。
数据
为了实现Conan-embedding-v2的多语言能力,我们收集了大量多样化的数据用于弱监督预训练和嵌入微调。
对于弱监督预训练,我们主要从新闻文章和网站中收集了标题-内容对,系统性地去除了低质量样本、冗余重复内容以及潜在有害信息。对于监督训练我们为五种不同任务组织了数据集:检索、重排序、分类、聚类和语义文本相似度(STS)。
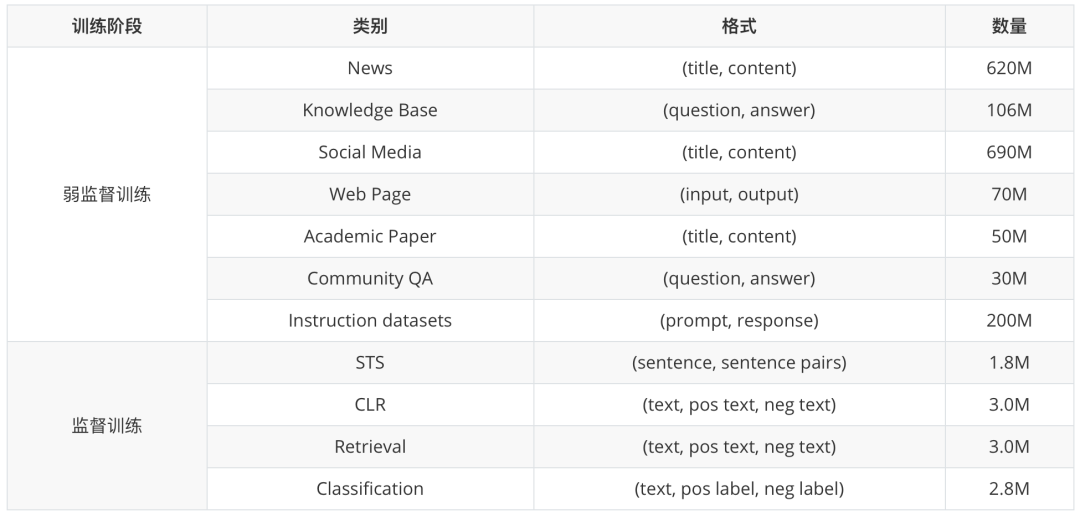
【表2】数据使用情况
实验结果主要结果

【表3】 MTEB中英结果
表3详细对比了我们的方法在MTEB-英文基准测试和MTEB-中文基准测试中的表现。Conan-embedding-v2在英文和中文的MTEB测试中均取得了SOTA结果,通过多种训练策略在CLS任务(英文91.11,中文76.8)和ReRank任务(英文51.49,中文73.69)中表现优异。
消融实验结果

【表4】 消融实验结果
表4通过消融实验系统地评估了框架中各个部分的贡献。 这些结果验证了Conan-embedding-v2组件在增强模型整体能力方面的协同效应。
仅使用跨语言检索任务目标(第2行)将多语言性能提升至62.69%(相比仅使用SM提升了1.96%),同时保持了稳定的单语言分数,证明了其在跨语言表示优化中的针对性能力。
仅使用动态硬负样本挖掘(第3行)在单一组件中取得了最佳的单语言结果(英文71.50%/中文72.09%),验证了其通过自适应负采样区分细粒度语义边界的有效性。
SM+CLR的组合(第4行)使多语言性能显著提升至64.45%(相比仅使用SM提升了3.56%)。
而SM+DHNM的组合(第5行)在完全整合之前达到了单语言分数的峰值。 然而,这两种部分组合揭示了多语言任务与单语言任务之间的精度权衡。
我们包含所有组件的完整框架(最后一行)通过协同结合SM的初始化稳定性、CLR的跨语言对齐以及DHNM的判别训练,解决了这一权衡,在所有任务中实现了SOTA性能。
和主流模型对比
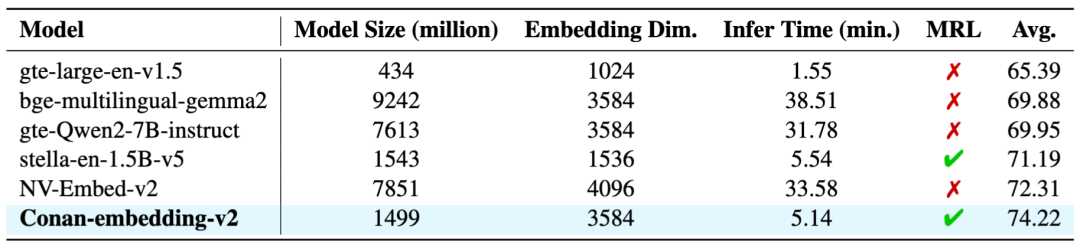
【表5】 主流模型对比
在表5中,我们对几种具有代表性的模型与我们的模型进行了比较。Conan-embedding-v2模型以其1503百万参数量(大约1.4B)和3584的Embedding维度取得SOTA。从模型规模、输出维度、推理时间、性能上展现出极佳的性能和平衡性。MRL和更长的输出维度也为模型在实际场景下的应用提供了更多的可能性。
结论和展望
本文介绍了Conan-embedding-v2,从LLM模型定义、词表训练、预训练到Embedding训练的全过程。解决了LLM与嵌入模型之间的数据和训练差距。 通过利用LLM训练的配对数据、用于弱监督嵌入训练的SoftMask、跨语言检索数据集以及用于监督嵌入训练的动态硬负样本挖掘,Conan-embedding-v2在保持较小模型规模和推理速度的同时,实现了SOTA性能。
Conan-Embedding-v1已在开源社区获得了广泛关注,帮助工作者在搜索、推荐、RAG等许多领域上取得收益。V2版本升级后,性能更强、能覆盖的场景更多,相信Conan-Embedding-v2可以进一步为相关领域工作者提供价值。欢迎大家与我们一同探索Conan Embedding在更多场景的应用!

转载请注明出处: CHATWEB
本文的链接地址: https://www.chatweb.com.cn/post-175.html
-

开抢!腾讯官宣 28000 HC!
5天前
-
扣子(coze)实战 | 用coze一键打造自己的口播数字人,操作简单方便(包含coze网页登录、声音克隆、数字人制作)
2025/04/19
-
我用AI「 高德 MCP+ cursor」 解决了日常最大难题“吃什么”!5分钟就搞定吃什么!
2025/04/19
-
深藏不露!Kimi这8个隐藏用法,高手都偷偷收藏了,再不学习就晚了!(上)
6天前
-
[AI工具箱] OneLine:一个由AI优化的时间线工具,如何帮你高效『吃瓜』?
5天前
-
华为电脑管家接入了四家大模型,却是“果篮式”的拼凑
2025/04/19
-
28000个实习岗位,腾讯发起史上最大就业计划
5天前
-
一文全懂:最牛AI公司OpenAI公司治理权斗背后的最创新股权设计
6天前
-
Kimi 16B胜GPT-4o!开源视觉推理模型:MoE架构,推理时仅激活2.8B
6天前
-
手把手教你写一篇头条号/公众号文章,从写作、排版、AI检测到发布
2025/04/19



![[AI工具箱] OneLine:一个由AI优化的时间线工具,如何帮你高效『吃瓜』?](https://www.chatweb.com.cn//content/uploadfile/x_wxgzh/20250421/6805c4e998ffc.jpg)






 EMLOG
EMLOG
暂无评论