
 AI资讯网小编
AI资讯网小编 上篇文章讲到了 DeepSeek+Dify 构建知识库的流程,通过 Dify 提供的分段和检索,可以将导入的文件生成知识库供 DeepSeek 进行查询和引用。这次我们来看看 Dify 的高级功能,通过知识库等功能实现更复杂的工作流。
工作流通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术和模型推理能力的依赖,提高了 LLM 应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性。
Dify 工作流分为两种类型:
- Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
- Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
今天我们会以一个 Chatflow 的例子来一步步看工作流是如何构建使用的。
工作流创建知识库由于该样例工作流依赖知识库,所以我们先创建两个知识库,分别用 DeepSeek 指导手册和 DeepSeek 赋能职场的文档来创建:
 创建工作流
创建工作流
现在来创建一个工作流,在工作室模块,点击从应用模版创建
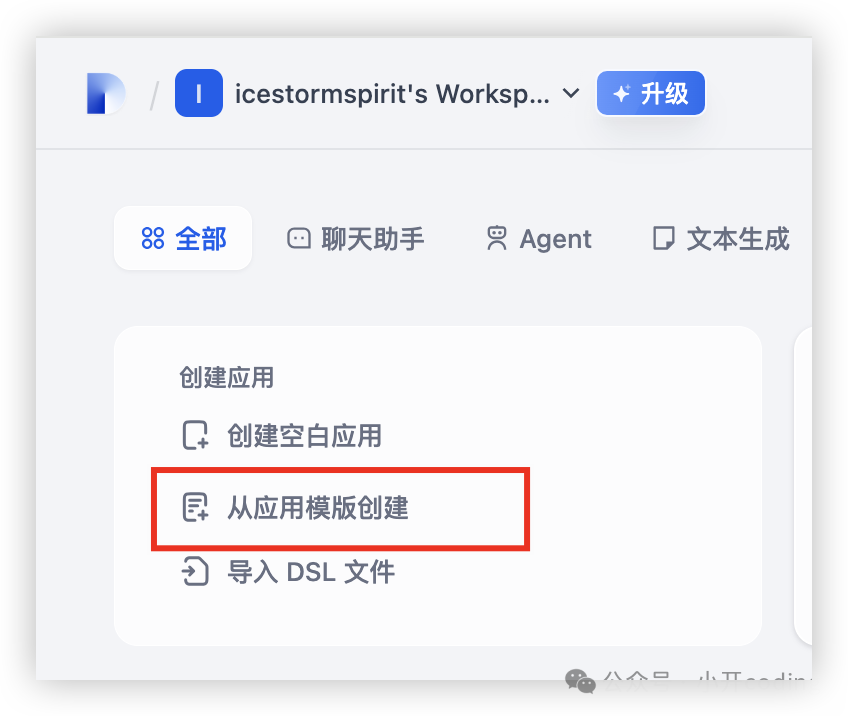
点击工作流,选择一个问题分类+知识库+聊天机器人的模板,创建。
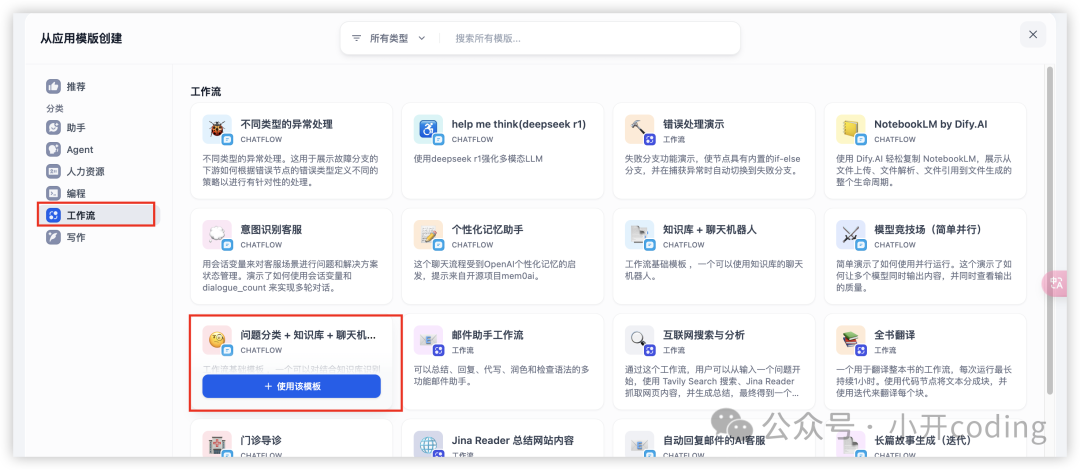
创建完成后会自动打开该工作流,进行编辑,点击开始节点,右边出现一堆字段:
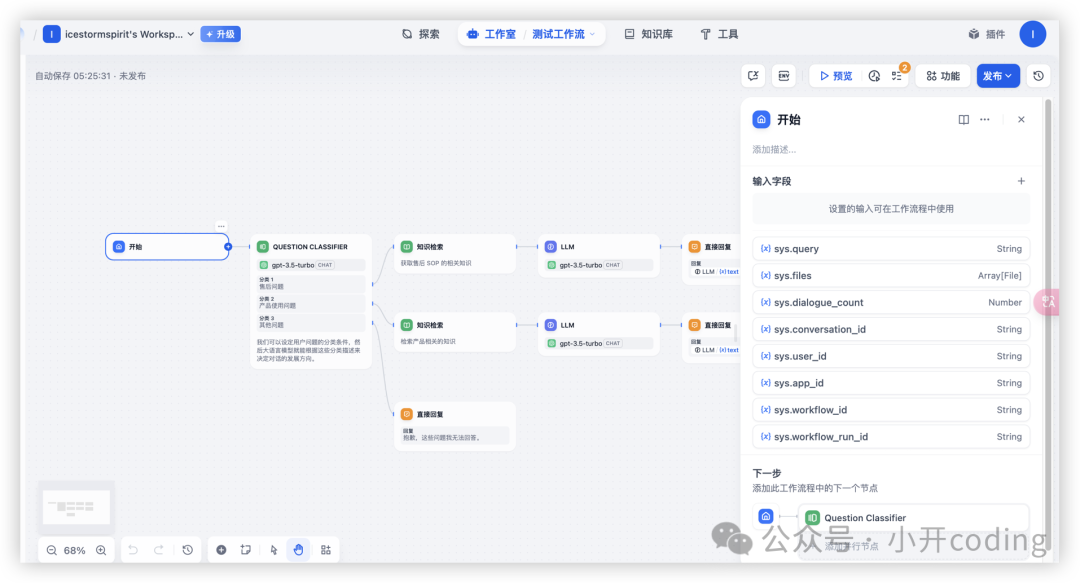
这些字段是变量,Dify 的变量一共有三种、分别是系统变量、环境变量和用户变量。
变量系统变量系统变量指的是在 Chatflow / Workflow 应用内预设的系统级参数,可以被其它节点全局读取。系统级变量均以 sys开头。
主要有:
sys.user_id:每个用户在使用工作流应用时,系统会自动向用户分配唯一标识符,用以区分不同的对话用户sys.app_id:系统会向每个 Workflow 应用分配一个唯一的标识符sys.workflow_id用于记录当前 Workflow 应用内所包含的所有节点信息sys.workflow_run_id用于记录 Workflow 应用中的运行情况
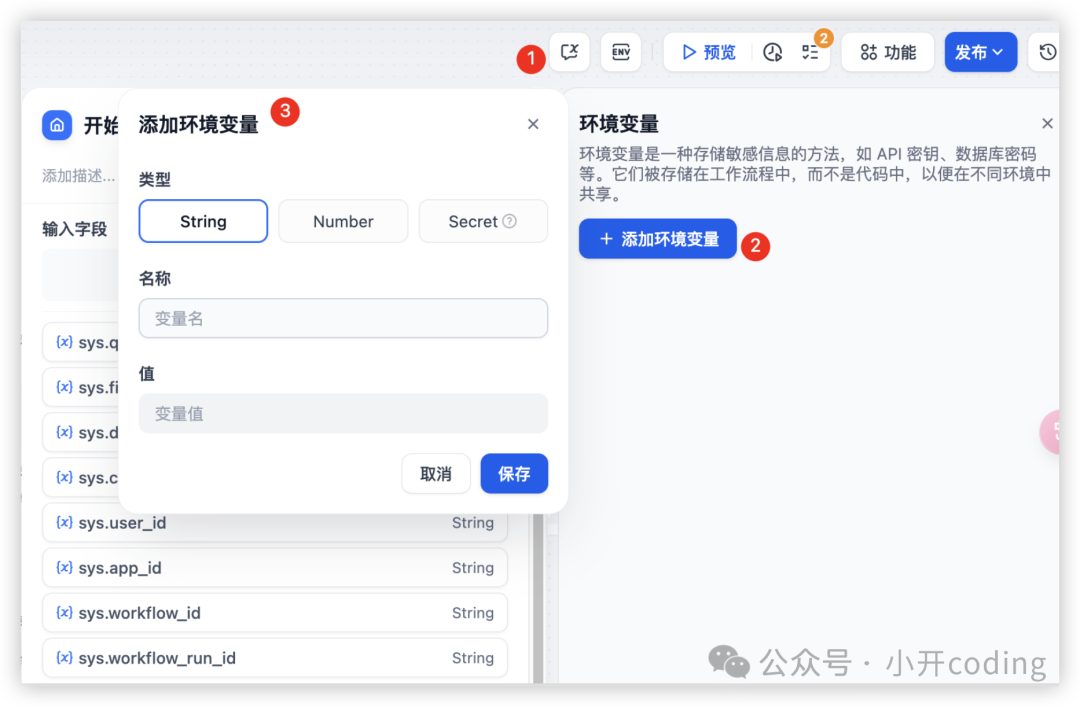
环境变量用于保护工作流内所涉及的敏感信息,例如运行工作流时所涉及的 API 密钥、数据库密码等。它们被存储在工作流程中,而不是代码中,以便在不同环境中共享。如下图所示可以添加环境变量:
 用户变量
用户变量
当我们需要用户传入一些特定的信息的时候,可以通过添加变量来实现。比如这里我们添加2个变量 use1、use2,用于给用户提问:
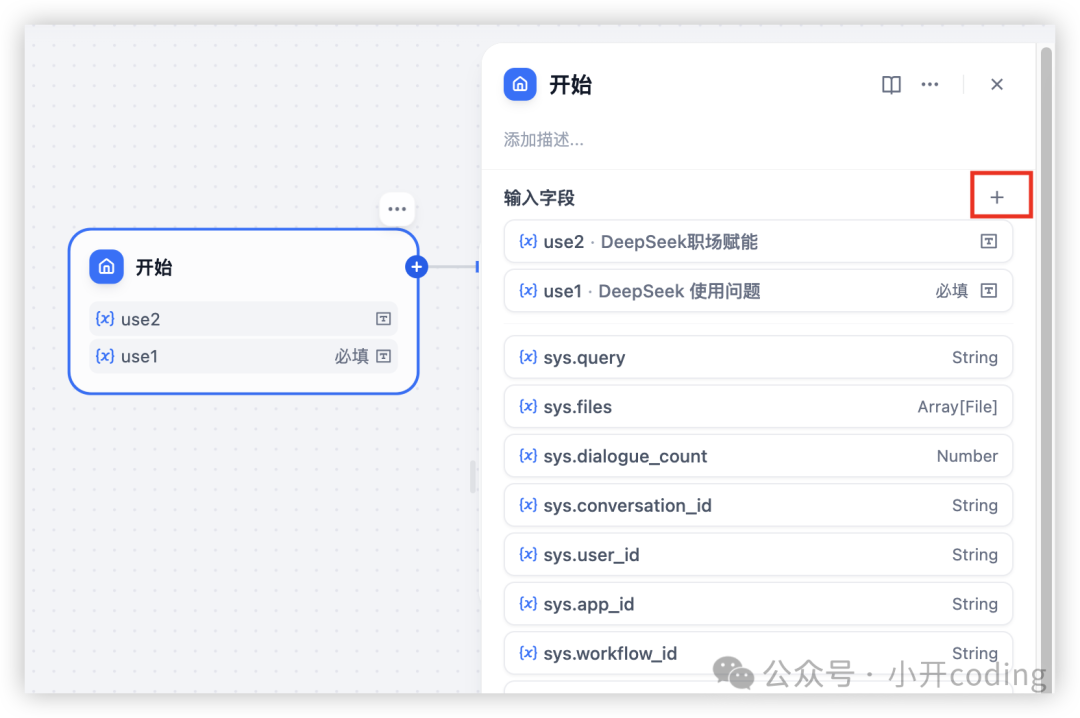
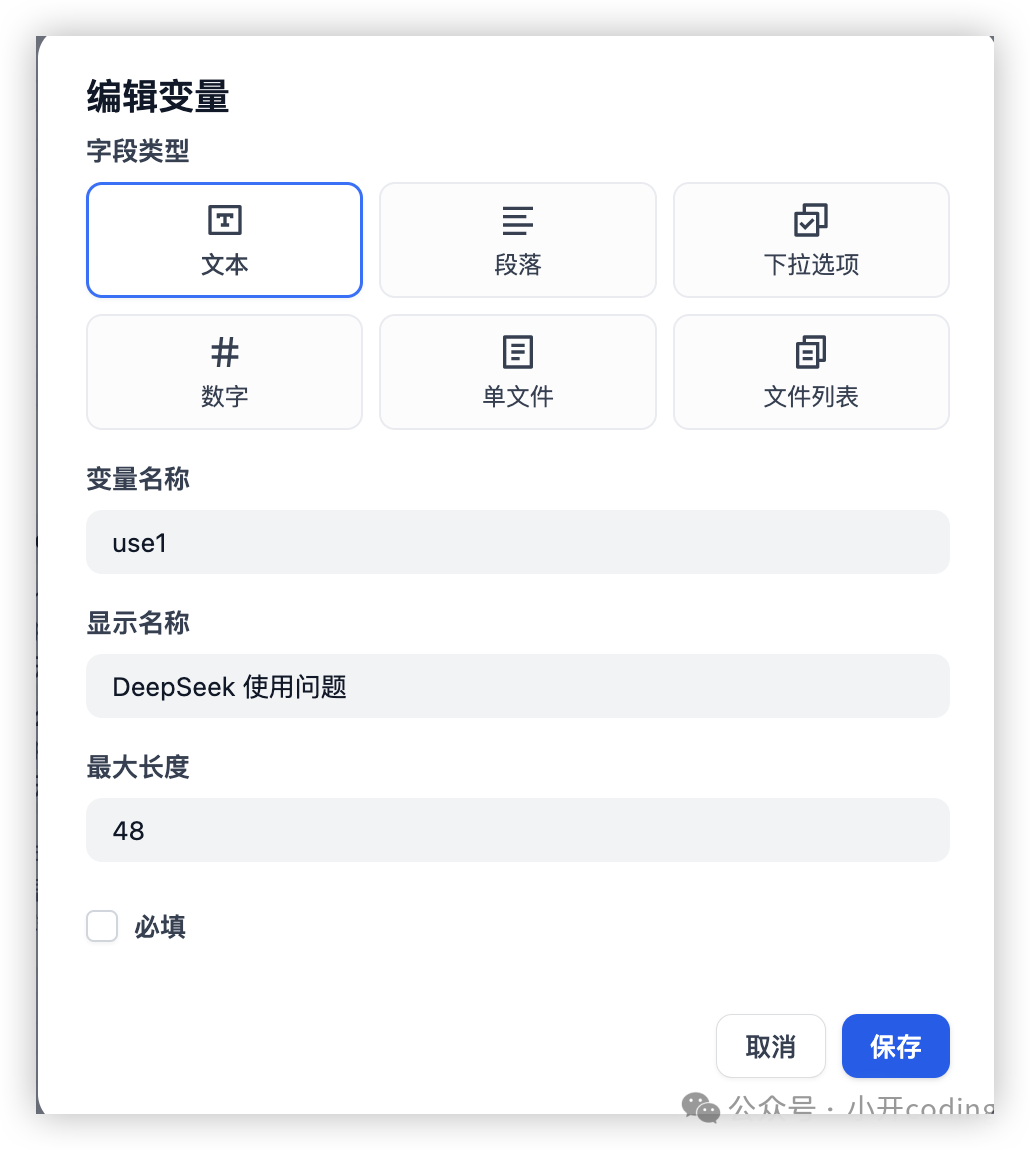
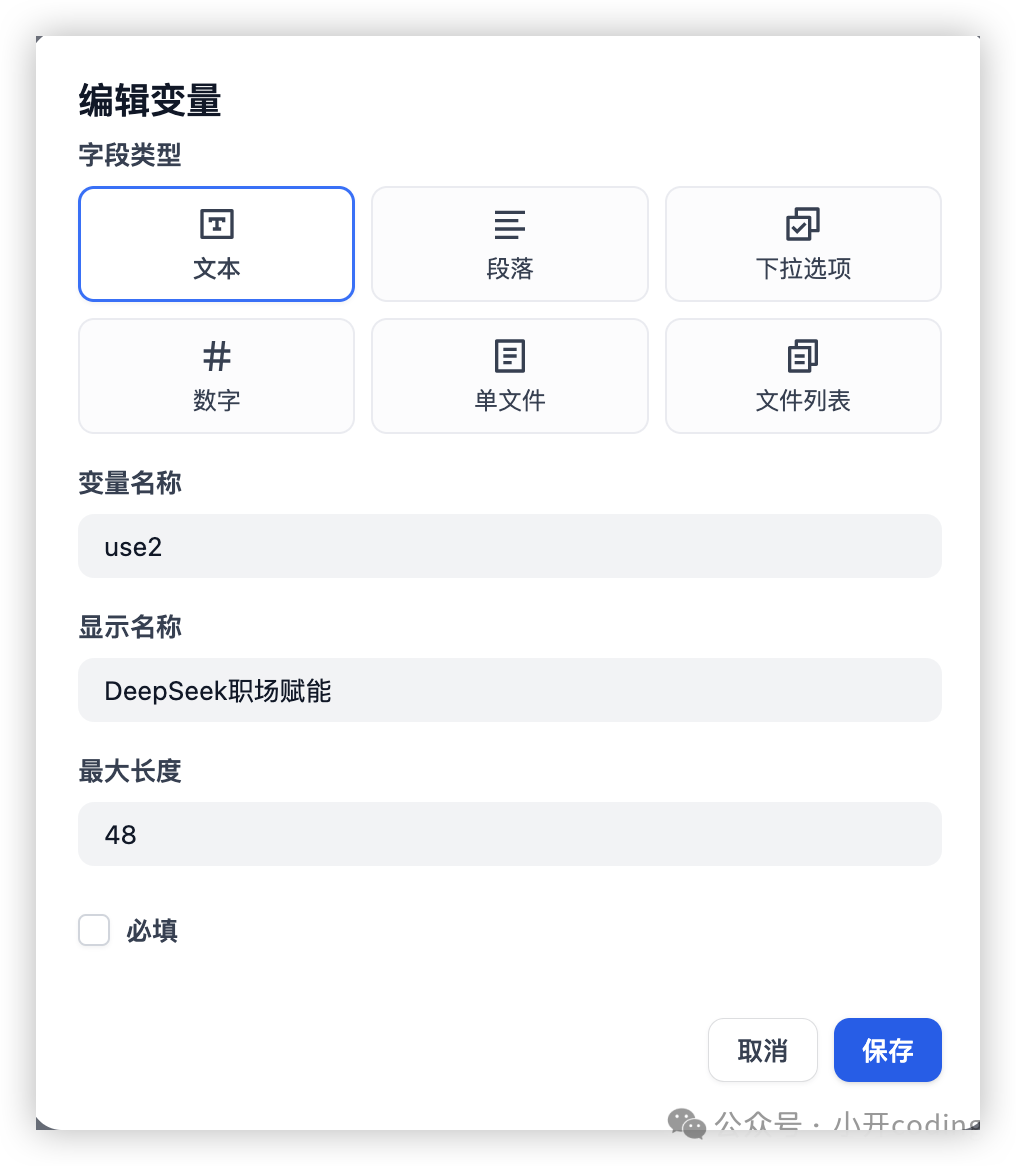
设置完用户变量之后,后面的节点就可以使用了。
这里介绍下各个节点的功能。
节点节点是工作流中的关键构成,通过连接不同功能的节点,执行工作流的一系列操作。在dify的工作流中一共有下面几种类型的节点。
开始节点刚刚已经看过了,开始节点主要是可以添加用户变量供后续节点使用。
问题分类器可以使用创建的知识库。问题分类器可以作为知识库检索的前置步骤,对用户输入问题意图进行分类处理,分类后导向下游不同的知识库查询相关的内容,以精确回复用户的问题。
比如这个工作流的第二个节点就是,我们可以这样配置:

选择推理模型,问题分类器基于大语言模型的自然语言分类和推理能力,选择合适的模型将有助于提升分类效果;
选择输入变量,指用于分类的输入内容,支持输入文件变量。问答场景下一般为用户输入的问题 sys.query;这里我们也选择 sys.query。
编写分类标签/描述,你可以手动添加多个分类,通过编写分类的关键词或者描述语句,让大语言模型更好的理解分类依据。这里我们选择两个分类,分别是使用问题和赋能职场。
分类里还可以使用变量,输入 / 即可弹出之前设置的变量。
高级设置,可以酌情使用,比如:
- 指令:你可以在 高级设置-指令里补充附加指令,比如更丰富的分类依据,以增强问题分类器的分类能力。
- 记忆:开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
- 图片分析:仅适用于具备图片识别能力的 LLM,允许输入图片变量。
从知识库中检索与用户问题相关的文本内容,可作为下游 LLM 节点的上下文来使用。比如工作流下一步节点:
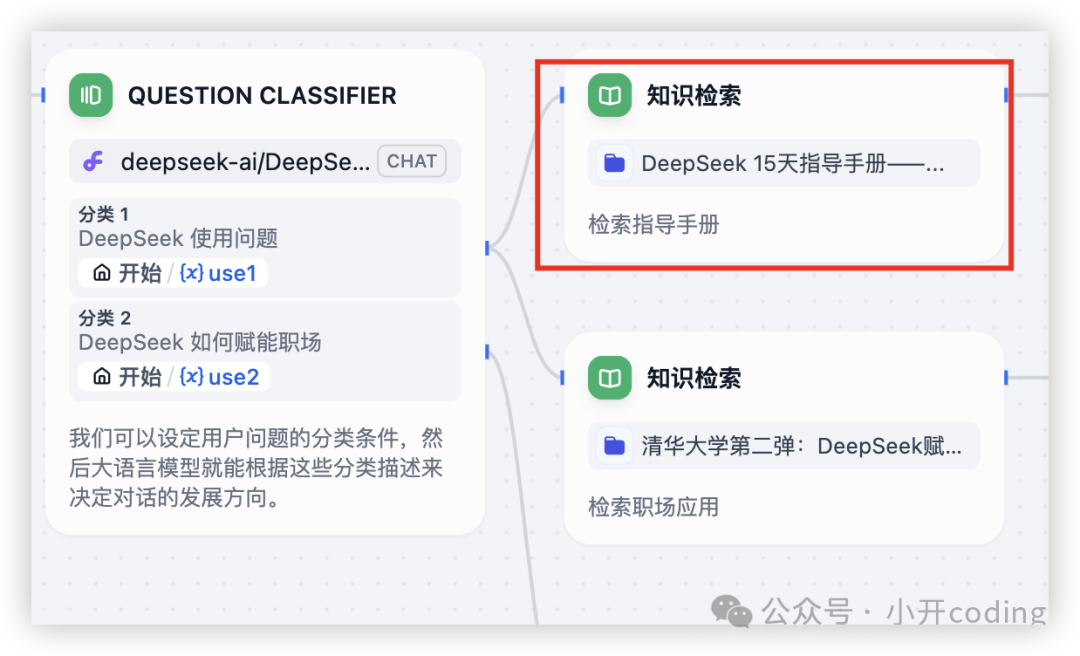
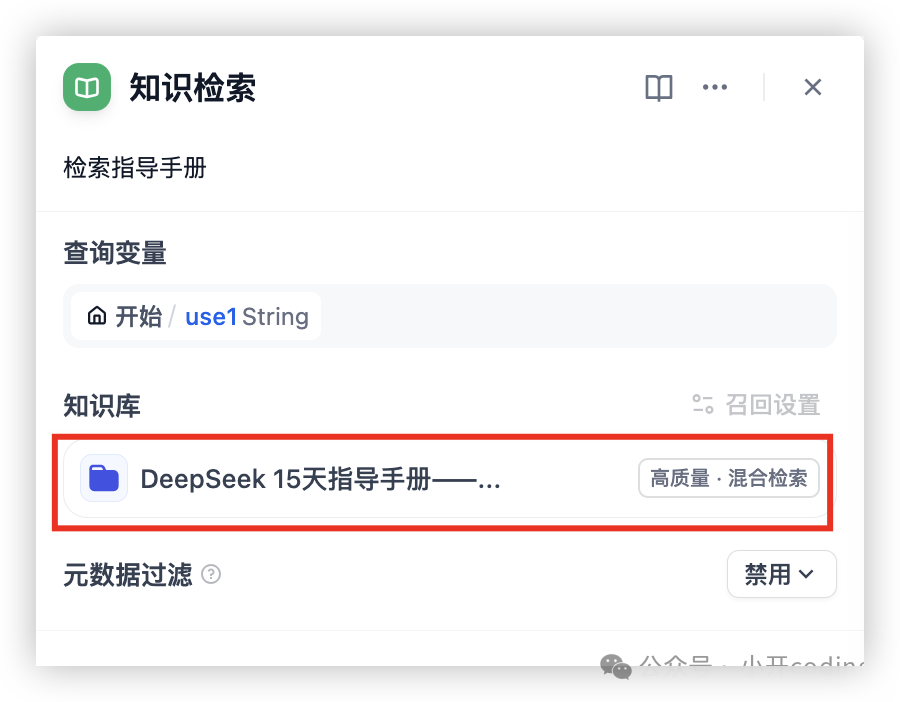
这里有两个知识检索节点,分别引用不同的知识库。点击召回设置可以设置知识库的召回策略:
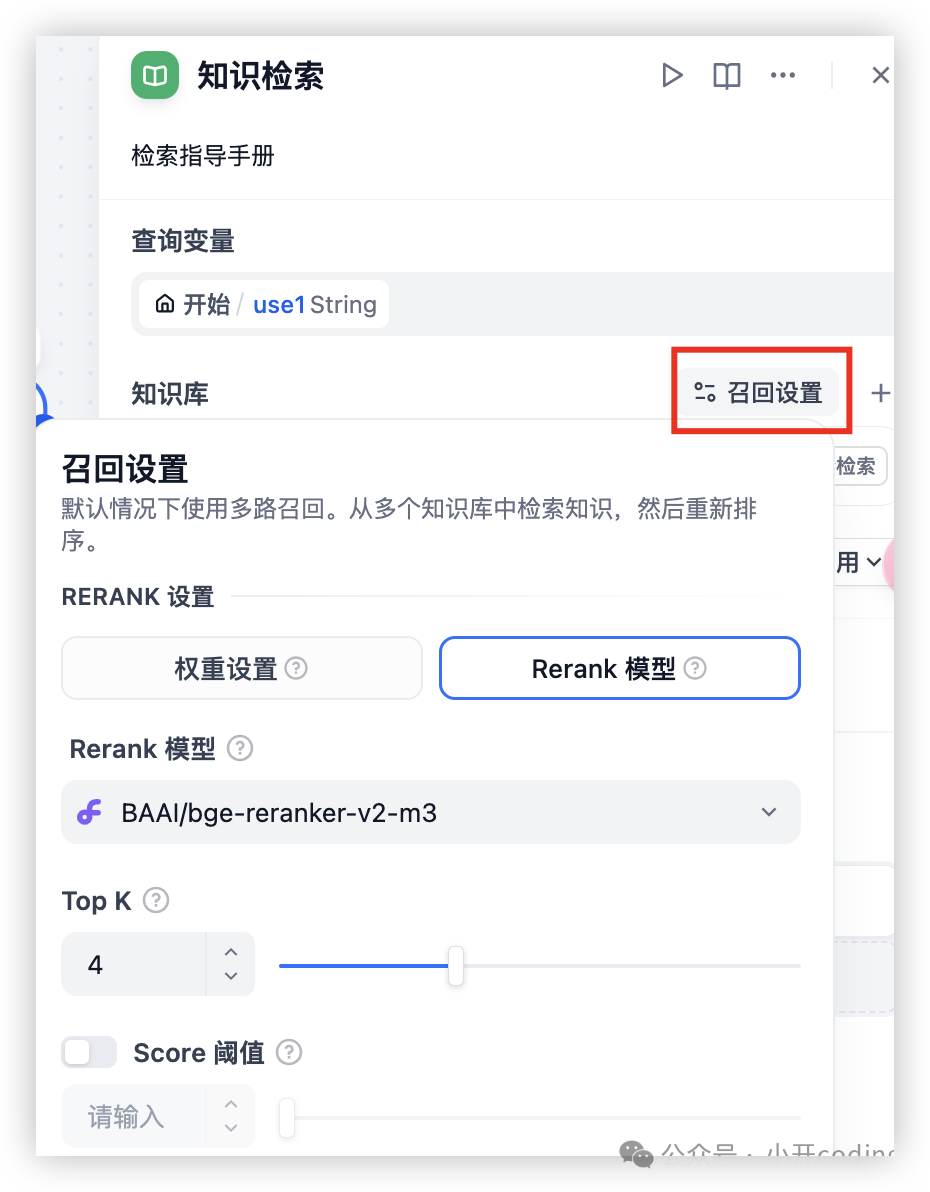
TopK代表按相似分数倒排时召回分段的最大个数。TopK 值调小,将会召回更少分段,可能导致召回的相关文本不全;TopK 值调大,将召回更多分段,可能导致召回语义相关性较低的分段使得 LLM 回复质量降低。召回阈值(Score)代表允许召回分段的最低相似分数。 召回分数调小,将会召回更多分段,可能导致召回相关度较低的分段;召回分数阈值调大,将会召回更少分段,过大时将会导致丢失相关分段。
这里先使用默认值。
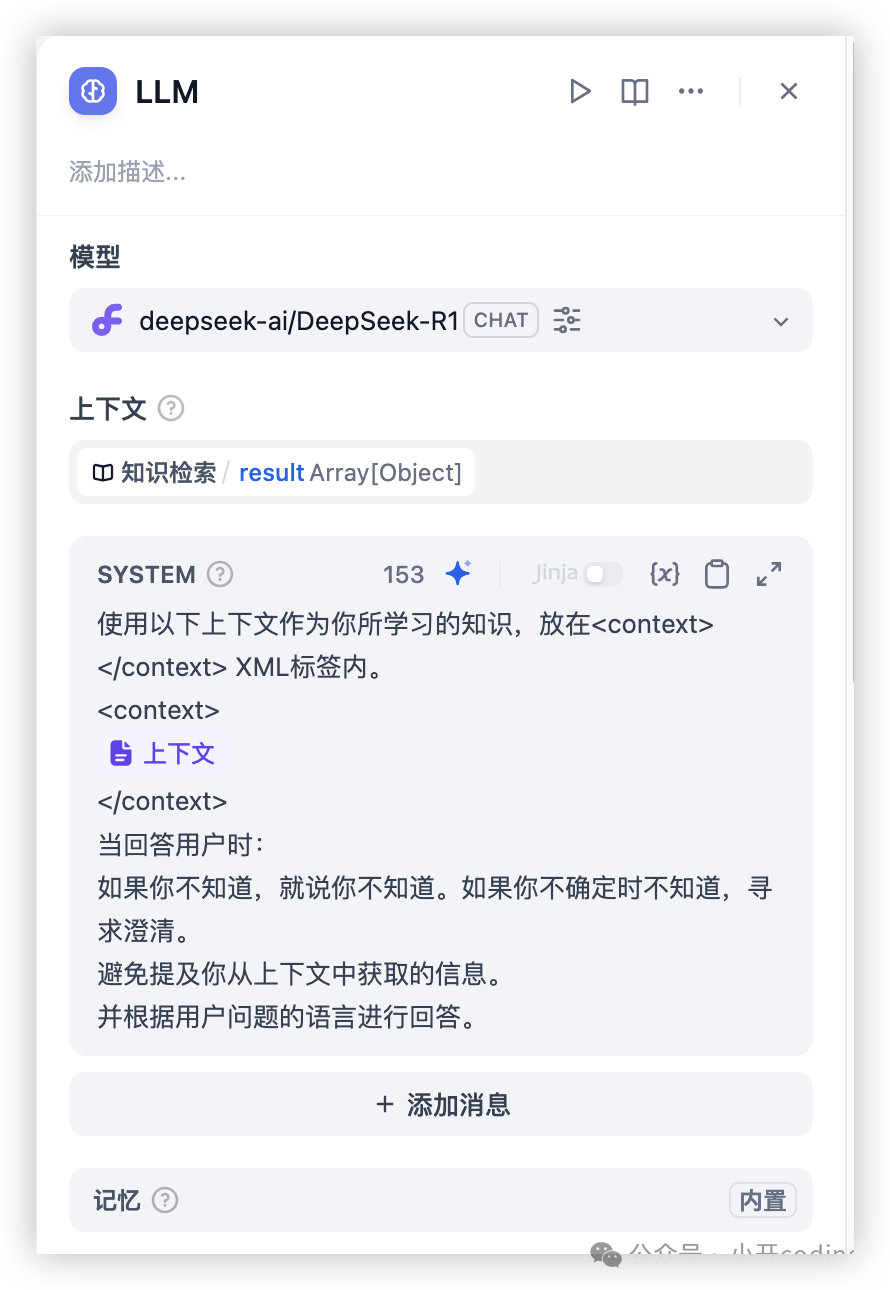
LLM 节点调用大语言模型的能力,处理用户在 “开始” 节点中输入的信息(自然语言、上传的文件或图片),给出有效的回应信息。
这里测试工作流的 LLM 节点配置成硅基流动的 DeepSeek:
该测试工作流主要使用的节点就是以上这些,还有一些比较常用的节点,这里也介绍一下:
条件分支主要用于流程节点中的逻辑判断。功能也很丰富,自主性特别高。

可以设置 IF ELIF ELSE 的条件变量,这里的意思就是 if sys.user_id == 1,else if sys.user_id == 2, else 这三种条件满足,分别会走到不同的节点。
HTTP 请求允许通过 HTTP 协议发送服务器请求,适用于获取外部数据、webhook、生成图片、下载文件等情景。它让你能够向指定的网络地址发送定制化的 HTTP 请求,实现与各种外部服务的互联互通。
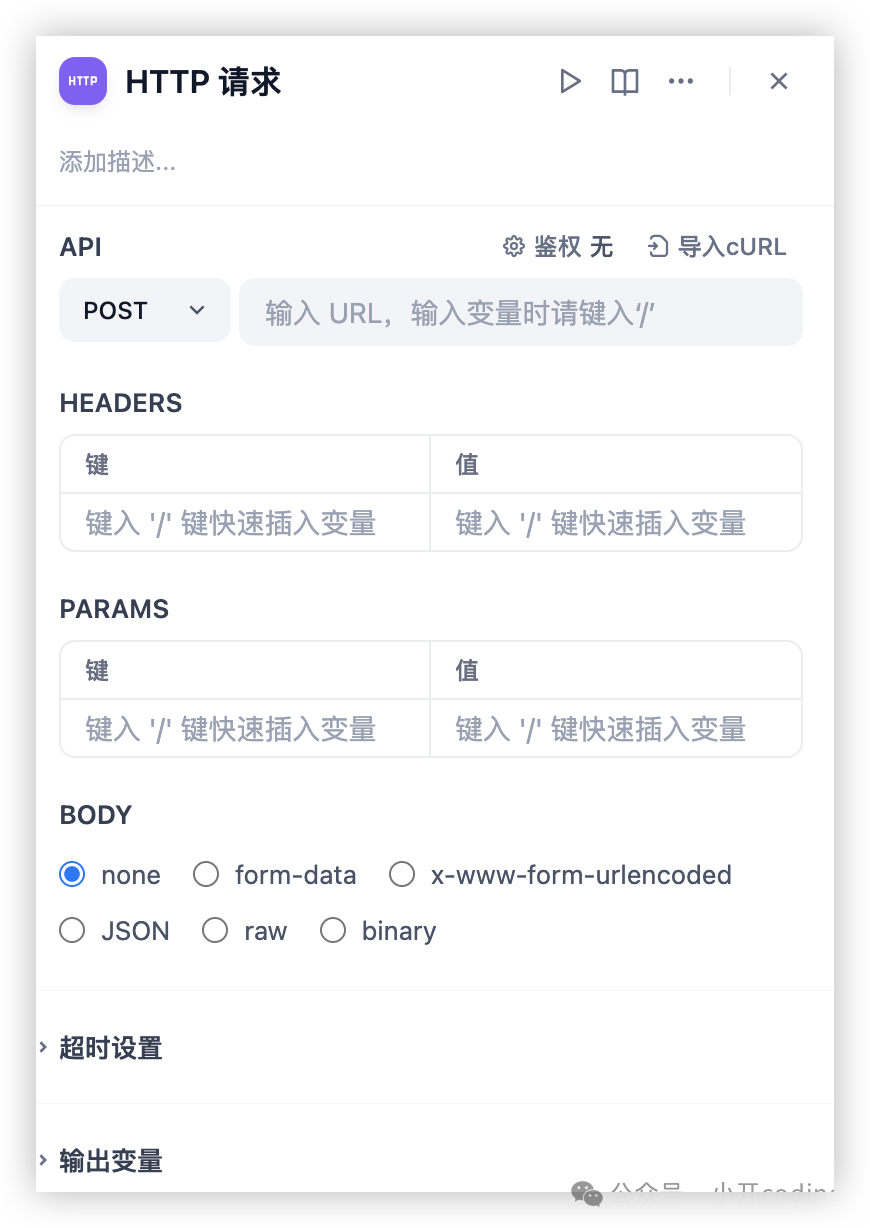
这里可以暴露接口给工作流使用,比如到了某一步调用一个接口设置状态或者插入数据库等。
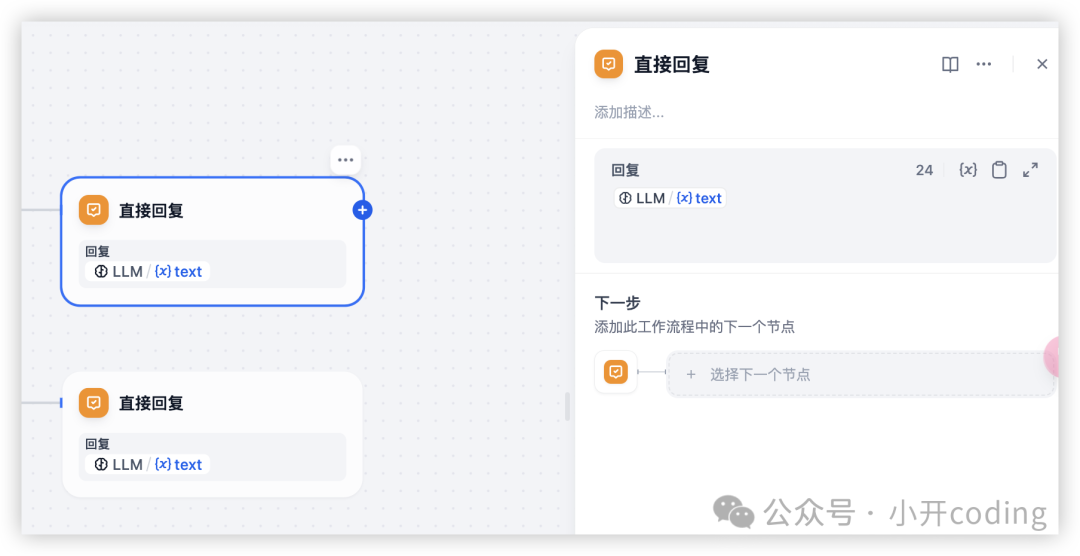
直接回复定义一个 Chatflow 流程中的回复内容。
这个就很简单了,我们工作流最后的节点就是这个,不需要设置,直接使用默认的即可。
 测试工作流
测试工作流
现在我们完整的工作流已经构建完成,现在来预览测试一下:
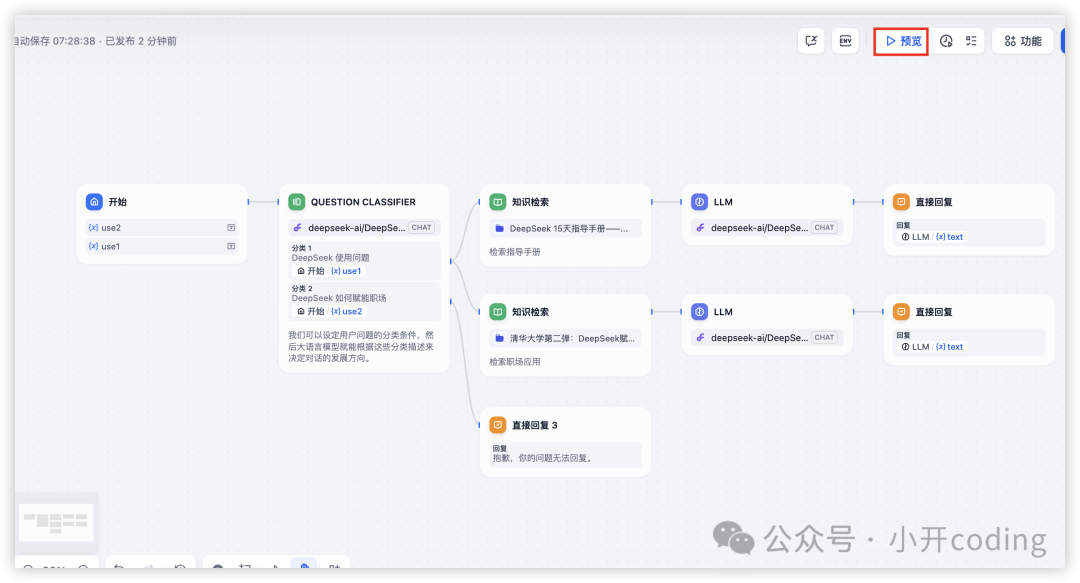
问一个简单的问题:
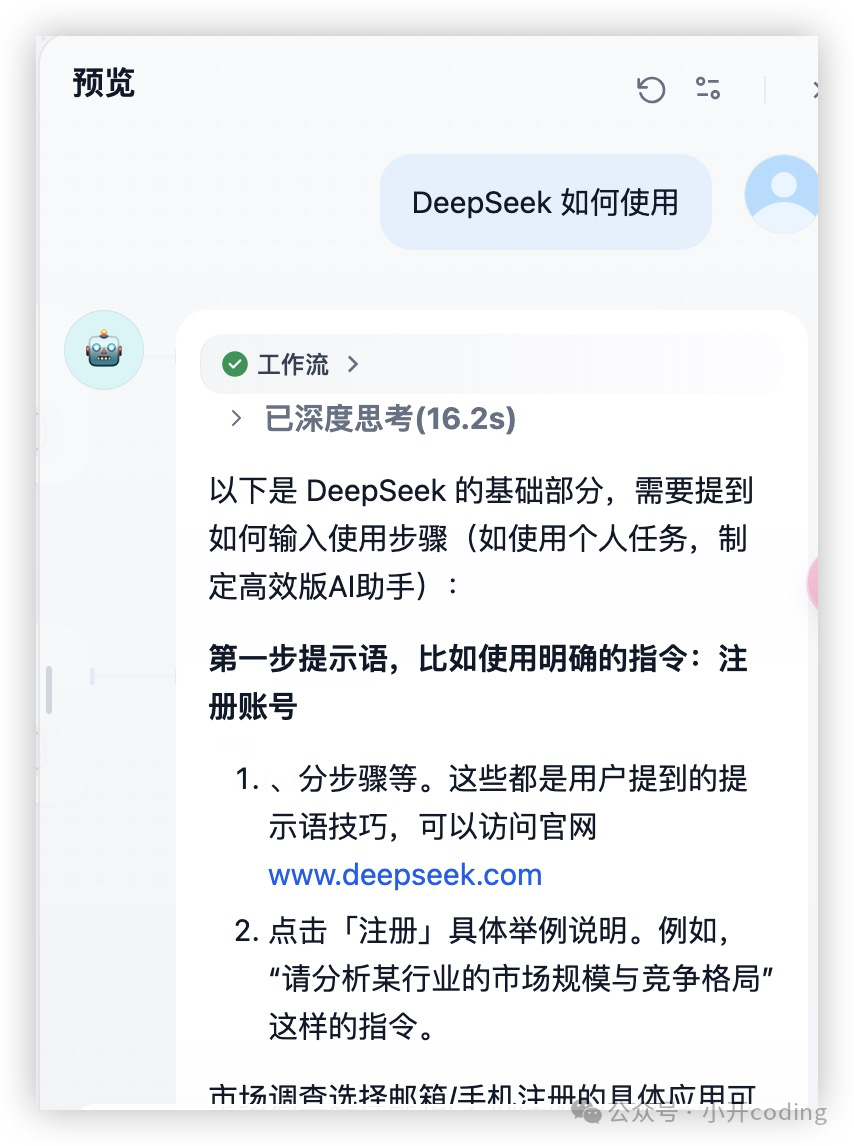

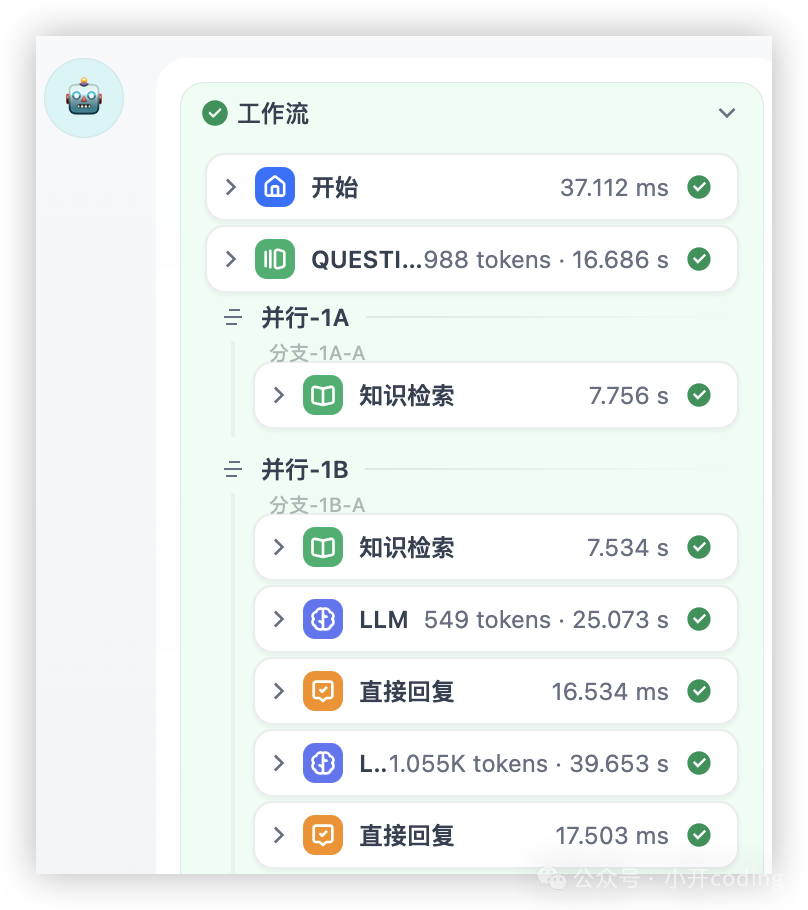
可以看出工作流正常完成,且通过知识库检索完成且引用到了知识库。
然后点击发布,就可以直接使用啦。
转载请注明出处: CHATWEB
本文的链接地址: https://www.chatweb.com.cn/post-49.html
-

推荐:一个先进的AI视频生成器!搞事情?
2025/04/06
-
GPT-4o杀疯了:现在修图靠‘说’就行!连我妈都做出了电商广告图
2025/03/30
-
DeepSeek新功能:批量生成视频,100个分镜视频只需几分钟!
2025/03/30
-
30家值得关注的AI公司精选了国内最值得关注的30家AI公司
2025/04/19
-
清华学霸团队出品的Kimi,好用到爆!
6天前
-
Prompt Optimizer:AI提示词优化工具
6天前
-
Google Gemini推出了Gems,可创建个人专属AI代理
5天前
-
Kimi的社区产品刚刚曝光,和OpenAI的是一件事吗?
6天前
-
GPT-4.1、Gemini 2.0 Flash、Claude 3.7 Sonnet等国际顶尖模型国内直充、无需科学上网
6天前
-
DeepSeek使用指南:从入门到精通
6天前










 EMLOG
EMLOG
暂无评论